
Apple’s $1299 beast from 2020 vs. identically-priced PC configuration - Which is faster for TensorFlow?
Apple’s M1 chip was an amazing technological breakthrough back in 2020. It hasn’t supported many tools data scientists need daily on launch, but a lot has changed since then. We even have the new M1 Pro and M1 Max chips tailored for professional users.
But can it actually compare with a custom PC with a dedicated GPU? That’s what we’ll answer today.
In today’s article, we’ll only compare data science use cases and ignore other laptop vs. PC differences. On the test we have a base model MacBook M1 Pro from 2020 and a custom PC powered by AMD Ryzen 5 and Nvidia RTX graphics card. Here are the specs:
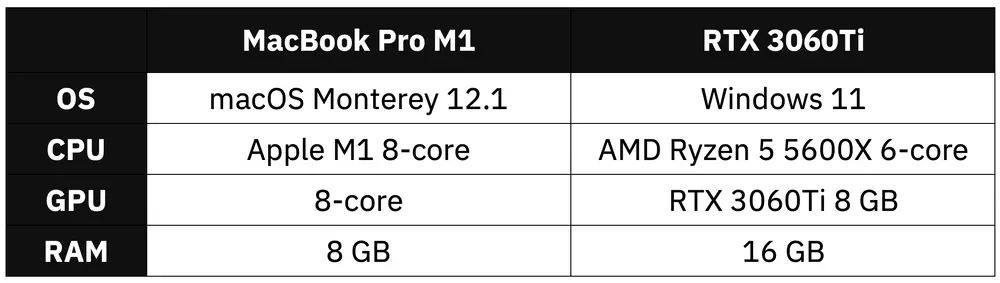
Image 1 - Hardware specification comparison (image by author)
Both machines are almost identically priced - I paid only $50 more for the custom PC. Budget-wise, we can consider this comparison fair.
Don’t feel like reading? Watch my video instead:
MacBook M1 vs. Custom PC - Geekbench
Synthetical benchmarks don’t necessarily portray real-world usage, but they’re a good place to start. Let’s first see how Apple M1 compares to AMD Ryzen 5 5600X in a single-core department:
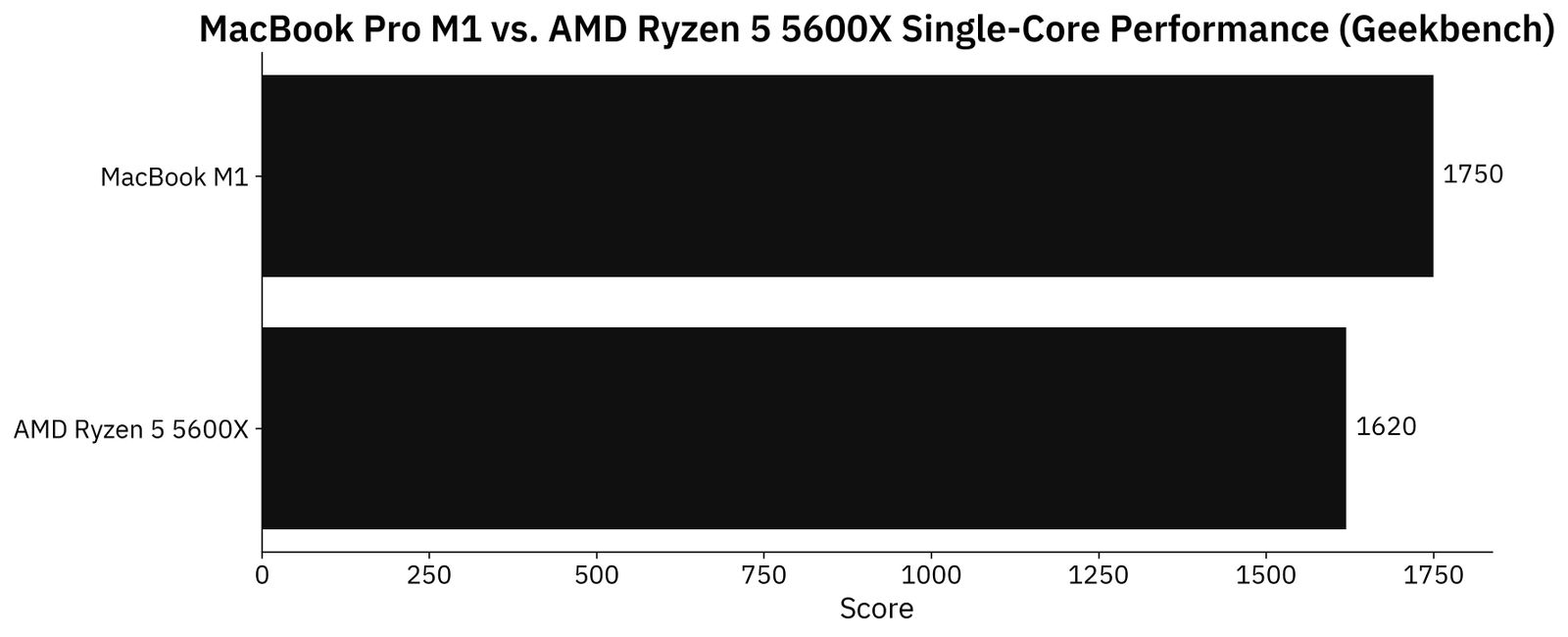
Image 2 - Geekbench single-core performance (image by author)
Apple M1 is around 8% faster on a synthetical single-core test, which is an impressive result. Keep in mind that we’re comparing a mobile chip built into an ultra-thin laptop with a desktop CPU.
Let’s compare the multi-core performance next. M1 has 8 cores (4 performance and 4 efficiency), while Ryzen has 6:

Image 3 - Geekbench multi-core performance (image by author)
M1 is negligibly faster - around 1.3%. We can conclude that both should perform about the same.
Here’s where they drift apart. Custom PC has a dedicated RTX3060Ti GPU with 8 GB of memory. A thin and light laptop doesn’t stand a chance:
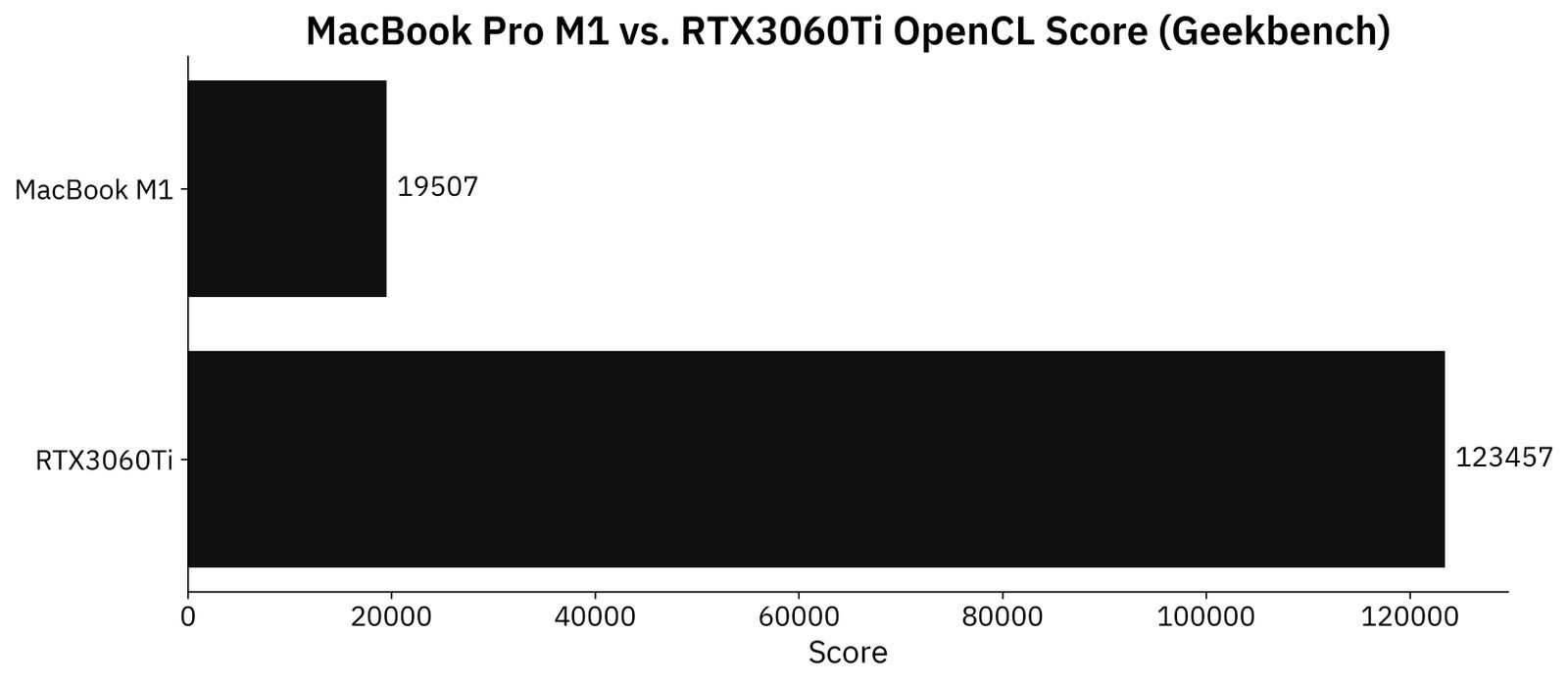
Image 4 - Geekbench OpenCL performance (image by author)
RTX3060Ti scored around 6.3X higher than the Apple M1 chip on the OpenCL benchmark. These results are expected. Heck, the GPU alone is bigger than the MacBook pro.
Overall, M1 is comparable to AMD Ryzen 5 5600X in the CPU department, but falls short on GPU benchmarks. We’ll have to see how these results translate to TensorFlow performance.
MacBook M1 vs. RTX3060Ti - Data Science Benchmark Setup
You’ll need TensorFlow installed if you’re following along. Here’s an entire article dedicated to installing TensorFlow for both Apple M1 and Windows:
Also, you’ll need an image dataset. I’ve used the Dogs vs. Cats dataset from Kaggle, which is licensed under the Creative Commons License. Long story short, you can use it for free.
Refer to the following article for detailed instructions on how to organize and preprocess it:
TensorFlow for Image Classification - Top 3 Prerequisites for Deep Learning Projects
We’ll do two tests today:
- TensorFlow with a custom model architecture - Uses two convolutional blocks described in my CNN article.
- TensorFlow with transfer learning - Uses VGG-16 pretrained network to classify images.
Let’s go over the code used in the tests.
Custom TensorFlow Model - The Code
I’ve split this test into two parts - a model with and without data augmentation. Use only a single pair of train_datagen and valid_datagen at a time:
import os
import warnings
from datetime import datetime
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
warnings.filterwarnings('ignore')
import numpy as np
import tensorflow as tf
tf.random.set_seed(42)
####################
# 1. Data loading
####################
# USED ON A TEST WITHOUT DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
# USED ON A TEST WITH DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
train_data = train_datagen.flow_from_directory(
directory='data/train/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
valid_data = valid_datagen.flow_from_directory(
directory='data/validation/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
####################
# 2. Model
####################
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), input_shape=(224, 224, 3), activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')]
)
####################
# 3. Training
####################
time_start = datetime.now()
model.fit(
train_data,
validation_data=valid_data,
epochs=5
)
time_end = datetime.now()
print(f'Duration: {time_end - time_start}')
Let’s go over the transfer learning code next.
Transfer Learning TensorFlow Model - The Code
Much of the imports and data loading code is the same. Once again, use only a single pair of train_datagen and valid_datagen at a time:
import os
import warnings
from datetime import datetime
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
warnings.filterwarnings('ignore')
import numpy as np
import tensorflow as tf
tf.random.set_seed(42)
####################
# 1. Data loading
####################
# USED ON A TEST WITHOUT DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
# USED ON A TEST WITH DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
train_data = train_datagen.flow_from_directory(
directory='data/train/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
valid_data = valid_datagen.flow_from_directory(
directory='data/validation/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
####################
# 2. Base model
####################
vgg_base_model = tf.keras.applications.vgg16.VGG16(
include_top=False,
input_shape=(224, 224, 3),
weights='imagenet'
)
for layer in vgg_base_model.layers:
layer.trainable = False
####################
# 3. Custom layers
####################
x = tf.keras.layers.Flatten()(vgg_base_model.layers[-1].output)
x = tf.keras.layers.Dense(128, activation='relu')(x)
out = tf.keras.layers.Dense(2, activation='softmax')(x)
vgg_model = tf.keras.models.Model(
inputs=vgg_base_model.inputs,
outputs=out
)
vgg_model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')]
)
####################
# 4. Training
####################
time_start = datetime.now()
vgg_model.fit(
train_data,
validation_data=valid_data,
epochs=5
)
time_end = datetime.now()
print(f'Duration: {time_end - time_start}')
Finally, let’s see the results of the benchmarks.
MacBook M1 vs. RTX3060Ti - Data Science Benchmark Results
We’ll now compare the average training time per epoch for both M1 and custom PC on the custom model architecture. Keep in mind that two models were trained, one with and one without data augmentation:
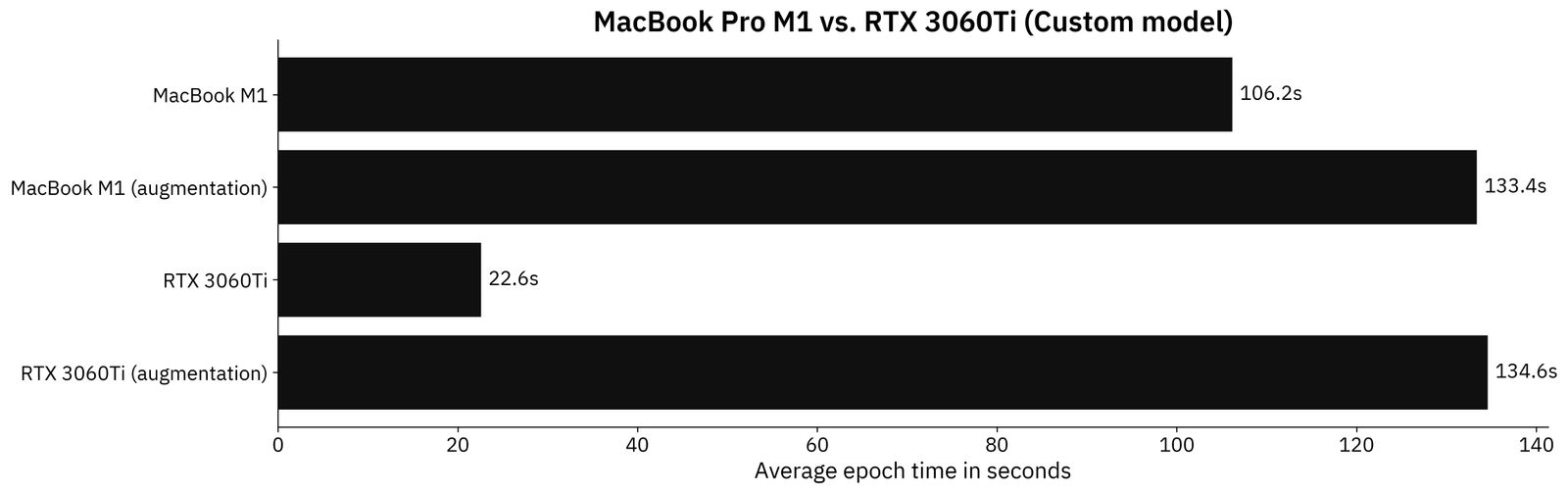
Image 5 - Custom model results in seconds (M1: 106.2; M1 augmented: 133.4; RTX3060Ti: 22.6; RTX3060Ti augmented: 134.6) (image by author)
One thing is certain - these results are unexpected. Don’t get me wrong, I expected RTX3060Ti to be faster overall, but I can’t reason why it’s running so slow on the augmented dataset.
On the non-augmented dataset, RTX3060Ti is 4.7X faster than the M1 MacBook. Both are roughly the same on the augmented dataset.
But who writes CNN models from scratch these days? Transfer learning is always recommended if you have limited data and your images aren’t highly specialized. Here are the results for the transfer learning models:
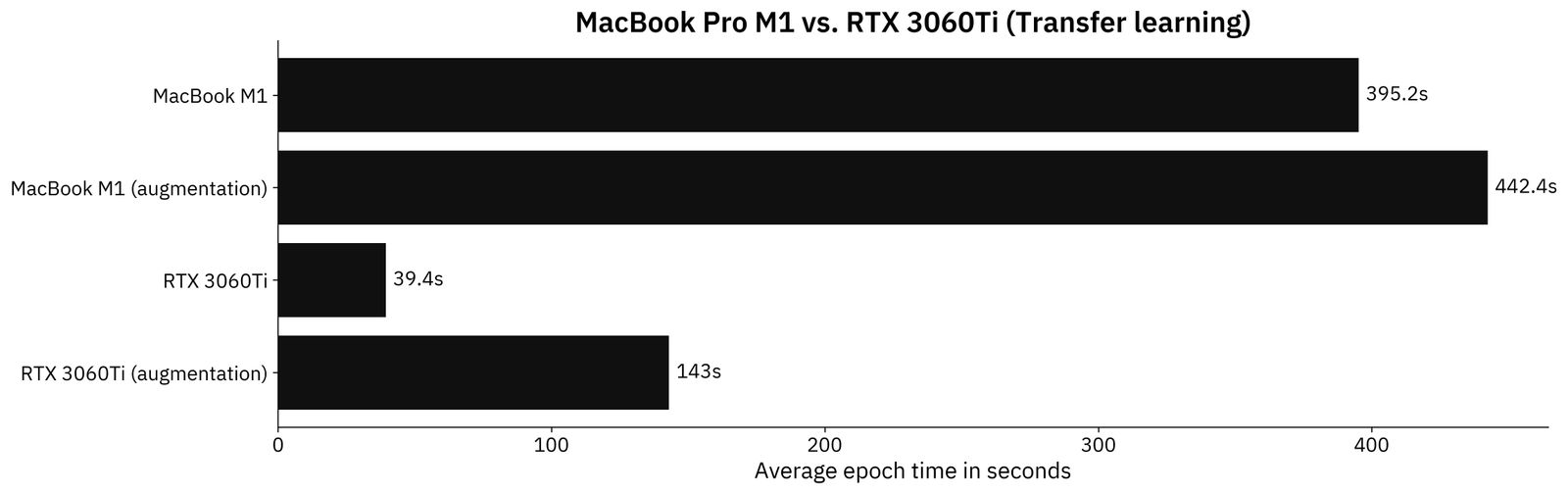
Image 6 - Transfer learning model results in seconds (M1: 395.2; M1 augmented: 442.4; RTX3060Ti: 39.4; RTX3060Ti augmented: 143) (image by author)
The results look more realistic this time. RTX3060Ti is 10X faster per epoch when training transfer learning models on a non-augmented image dataset. For the augmented dataset, the difference drops to 3X faster in favor of the dedicated GPU.
Still, these results are more than decent for an ultralight laptop that wasn’t designed for data science in the first place. We knew right from the start that M1 doesn’t stand a chance.
Parting Words
Apple’s M1 chip is remarkable - no arguing there. Nothing comes close if we compare the compute power per wat. Still, if you need decent deep learning performance, then going for a custom desktop configuration is mandatory. The only way around it is renting a GPU in the cloud, but that’s not the option we explored today.
RTX3060Ti from NVIDIA is a mid-tier GPU that does decently for beginner to intermediate deep learning tasks. Sure, you won’t be training high-resolution style GANs on it any time soon, but that’s mostly due to 8 GB of memory limitation. RTX3090Ti with 24 GB of memory is definitely a better option, but only if your wallet can stretch that far.
Mid-tier will get you most of the way, most of the time.
What are your thoughts on this benchmark? Can you run it on a more powerful GPU and share the results? Let me know in the comment section below.
Learn More
- Benchmark: MacBook M1 vs. M1 Pro for Data Science
- Benchmark: MacBook M1 vs. Google Colab for Data Science
- Benchmark: MacBook M1 Pro vs. Google Colab for Data Science
Stay connected
- Sign up for my newsletter
- Subscribe on YouTube
- Connect on LinkedIn