
Apple’s $1299 beast from 2020 vs. a completely free environment - Which is faster for TensorFlow?
Apple’s M1 chip was an amazing technological breakthrough back in 2020. It hasn’t supported many tools data scientists need daily on launch, but a lot has changed since then. We even have the new M1 Pro and M1 Max chips tailored for professional users.
But what’s the point of an expensive laptop if you can do everything in the cloud?
Today we’ll only compare data science use cases and ignore the other scenarios in which a laptop is more practical than a cloud environment. On the test we have a base model MacBook M1 from 2020 and Google Colab with a GPU environment. Here are the specs:
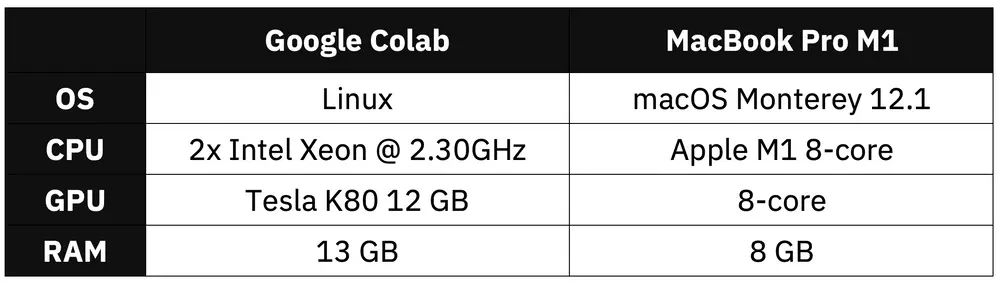
Image 1 - Hardware specification comparison (image by author)
Google Colab environment looks better on paper - no arguing there. We’ll have to see how it translates for training image classification models with TensorFlow.
Keep in mind: The Colab environment that was assigned to me is completely random. You’re likely to get a different one, so the benchmark results may vary.
Don’t feel like reading? Watch my video instead:
MacBook M1 vs. Google Colab - Data Science Benchmark Setup
You’ll need TensorFlow installed if you’re following along. Here’s an entire article dedicated to installing TensorFlow on Apple M1:
How To Install TensorFlow 2.7 on MacBook Pro M1 Pro With Ease
Also, you’ll need an image dataset. I’ve used the Dogs vs. Cats dataset from Kaggle, which is licensed under the Creative Commons License. Long story short, you can use it for free.
Refer to the following article for detailed instructions on how to organize and preprocess it:
TensorFlow for Image Classification - Top 3 Prerequisites for Deep Learning Projects
We’ll do two tests today:
- TensorFlow with a custom model architecture - Uses two convolutional blocks described in my CNN article.
- TensorFlow with transfer learning - Uses VGG-16 pretrained network to classify images.
Let’s go over the code used in the tests.
Custom TensorFlow Model - The Code
I’ve split this test into two parts - a model with and without data augmentation. Use only a single pair of train_datagen and valid_datagen at a time:
import os
import warnings
from datetime import datetime
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
warnings.filterwarnings('ignore')
import numpy as np
import tensorflow as tf
tf.random.set_seed(42)
# COLAB ONLY
from google.colab import drive
drive.mount('/content/drive')
####################
# 1. Data loading
####################
# USED ON A TEST WITHOUT DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
# USED ON A TEST WITH DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
train_data = train_datagen.flow_from_directory(
directory='data/train/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
valid_data = valid_datagen.flow_from_directory(
directory='data/validation/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
####################
# 2. Model
####################
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), input_shape=(224, 224, 3), activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')]
)
####################
# 3. Training
####################
time_start = datetime.now()
model.fit(
train_data,
validation_data=valid_data,
epochs=5
)
time_end = datetime.now()
print(f'Duration: {time_end - time_start}')
Let’s go over the transfer learning code next.
Transfer Learning TensorFlow Model - The Code
Much of the imports and data loading code is the same. Once again, use only a single pair of train_datagen and valid_datagen at a time:
import os
import warnings
from datetime import datetime
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
warnings.filterwarnings('ignore')
import numpy as np
import tensorflow as tf
tf.random.set_seed(42)
# COLAB ONLY
from google.colab import drive
drive.mount('/content/drive')
####################
# 1. Data loading
####################
# USED ON A TEST WITHOUT DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
# USED ON A TEST WITH DATA AUGMENTATION
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
train_data = train_datagen.flow_from_directory(
directory='data/train/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
valid_data = valid_datagen.flow_from_directory(
directory='data/validation/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
####################
# 2. Base model
####################
vgg_base_model = tf.keras.applications.vgg16.VGG16(
include_top=False,
input_shape=(224, 224, 3),
weights='imagenet'
)
for layer in vgg_base_model.layers:
layer.trainable = False
####################
# 3. Custom layers
####################
x = tf.keras.layers.Flatten()(vgg_base_model.layers[-1].output)
x = tf.keras.layers.Dense(128, activation='relu')(x)
out = tf.keras.layers.Dense(2, activation='softmax')(x)
vgg_model = tf.keras.models.Model(
inputs=vgg_base_model.inputs,
outputs=out
)
vgg_model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')]
)
####################
# 4. Training
####################
time_start = datetime.now()
vgg_model.fit(
train_data,
validation_data=valid_data,
epochs=5
)
time_end = datetime.now()
print(f'Duration: {time_end - time_start}')
Finally, let’s see the results of the benchmarks.
MacBook M1 vs. Google Colab - Data Science Benchmark Results
We’ll now compare the average training time per epochs for both M1 and Google Colab on the custom model architecture. Keep in mind that two models were trained, one with and one without data augmentation:
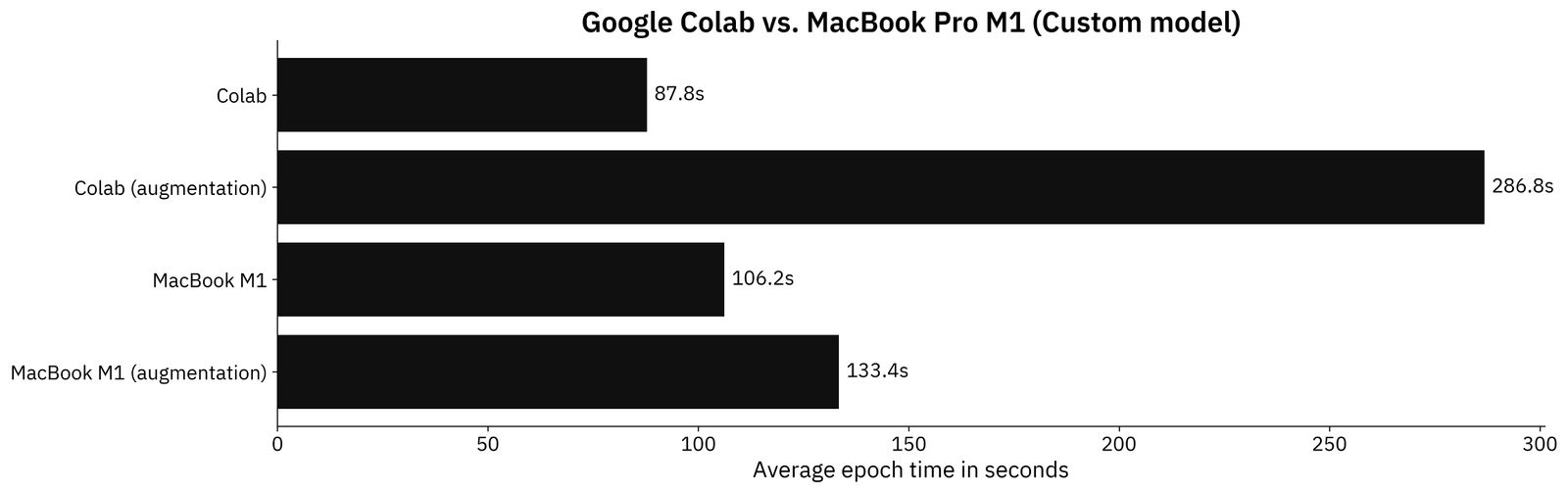
Image 2 - Benchmark results - custom model (image by author)
MacBook M1 turned out to be around 20% slower on the non-augmented image set, but completely moped the flor with Colab on the augmented one. M1 was overall more consistent.
But who writes CNN models from scratch these days? Transfer learning is always recommended if you have limited data and your images aren’t highly specialized. Here are the results for the transfer learning models:
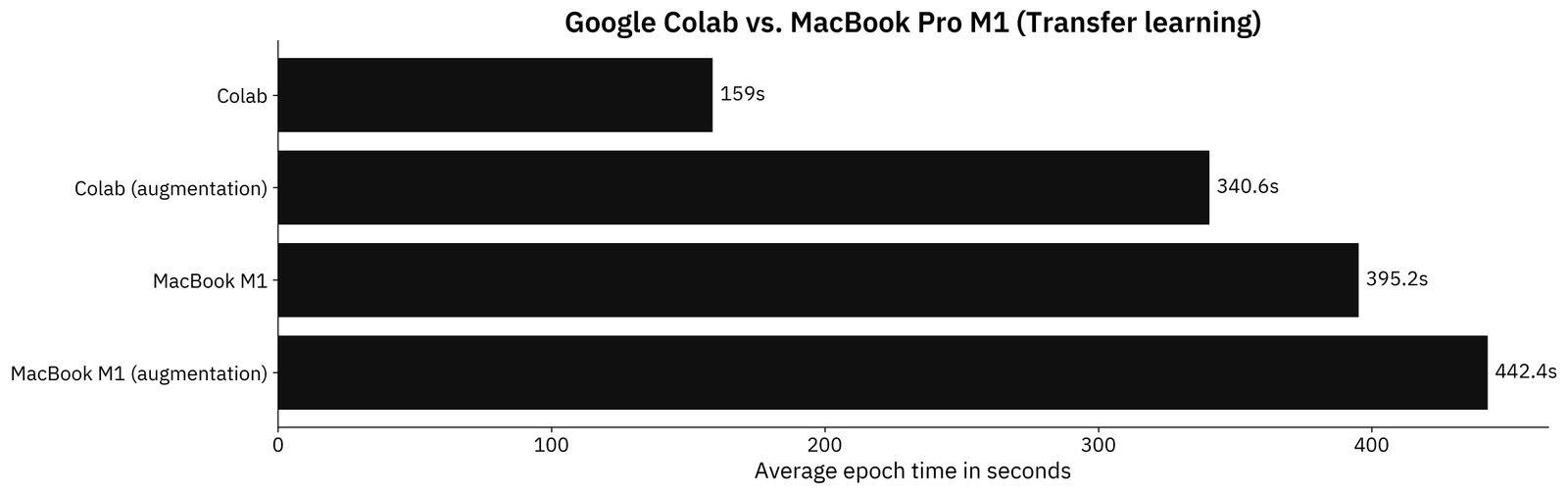
Image 3 - Benchmark results - transfer learning model (image by author)
Thinks don’t look good for the M1 MacBook. Google Colab is significantly faster due to a dedicated GPU. M1 has an 8-core GPU, but it’s nowhere near capable as TESLA from NVIDIA.
Still, I have to admit that seeing these results is impressive for a thin and light laptop that wasn’t designed for data science and machine learning. 2021’s M1 Pro model handles these tasks much better.
Parting Words
Yes, you definitely can use the 13" M1 Macbook Pro (and even Air) from 2020 for data science and machine learning - at least for the lighter tasks. If you only care about these two areas, then M1 probably isn’t the most cost-effective option. Google Colab is completely free, and it outperformed M1 in most of the tests done today.
If you’re looking for a laptop that can handle typical data science workloads and doesn’t scream cheap plastic and unnecessary red details, M1 might be the best option. It’s fast, responsive, light, has a superb screen, and all-day battery life. Plus, you can definitely use it for data science. It comes with a hefty price tag, sure, but they offer a lot of things Windows laptops just can’t match.
What are your thoughts on the best portable data science environment? Good all-rounder like M1 + cloud for heavier use, or a cheaper laptop + more time in the cloud? Or something in between? Let me know in the comment section below.
Stay connected
- Sign up for my newsletter
- Subscribe on YouTube
- Connect on LinkedIn