
Pandas and TensorFlow benchmarks on Intel i3-6100U vs. M1 Pro MacBook Pro - Up to 50X faster?
The 16" M1 Pro MacBook has been my go-to workhorse since its launch. It packs incredible performance below the ultra-premium surface - all while lasting an entire day and having probably the best screen in the industry.
But what about an old, dual-core Lenovo ThinkPad? Can a sixth-generation Intel processor even come close to a modern-day powerhouse? Continue reading to find out.
In today’s article, we’ll compare an old ThinkPad L470 to a modern M1 Pro MacBook Pro in a series of benchmarks, from synthetic ones to Pandas and TensorFlow. The scope of the benchmarks will be limited, so everything can fit in a ten-minute read.
Before going any further, let’s compare the hardware specs:
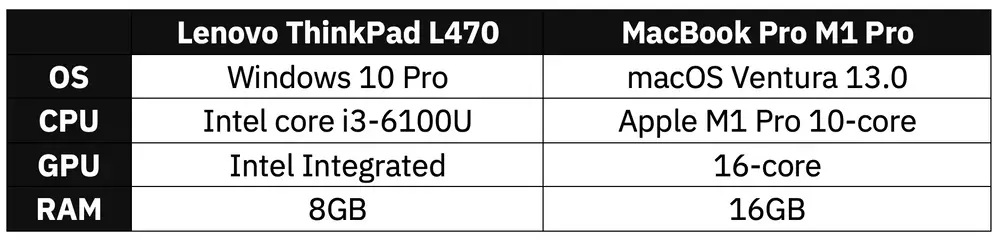
Image 1 - Hardware specification comparison (image by author)
It’s not really an apples-to-apples comparison. The Mac starts at $2499, and I bought the ThinkPad for under $200. That’s over 12x cheaper, so the Mac has some justification to do.
Don’t feel like reading? Watch my video instead:
Intel core i3-6100U on a Benchmark - Not so Great Nowadays
The 6100U was released way back in 2015, so we really can’t expect it to compare well over a much more modern and powerful chip. Also, synthetical benchmarks can only take us so far, but they’re a good starting point.
Here’s how i3-6100U compares to the M1 Pro chip in a single core department:
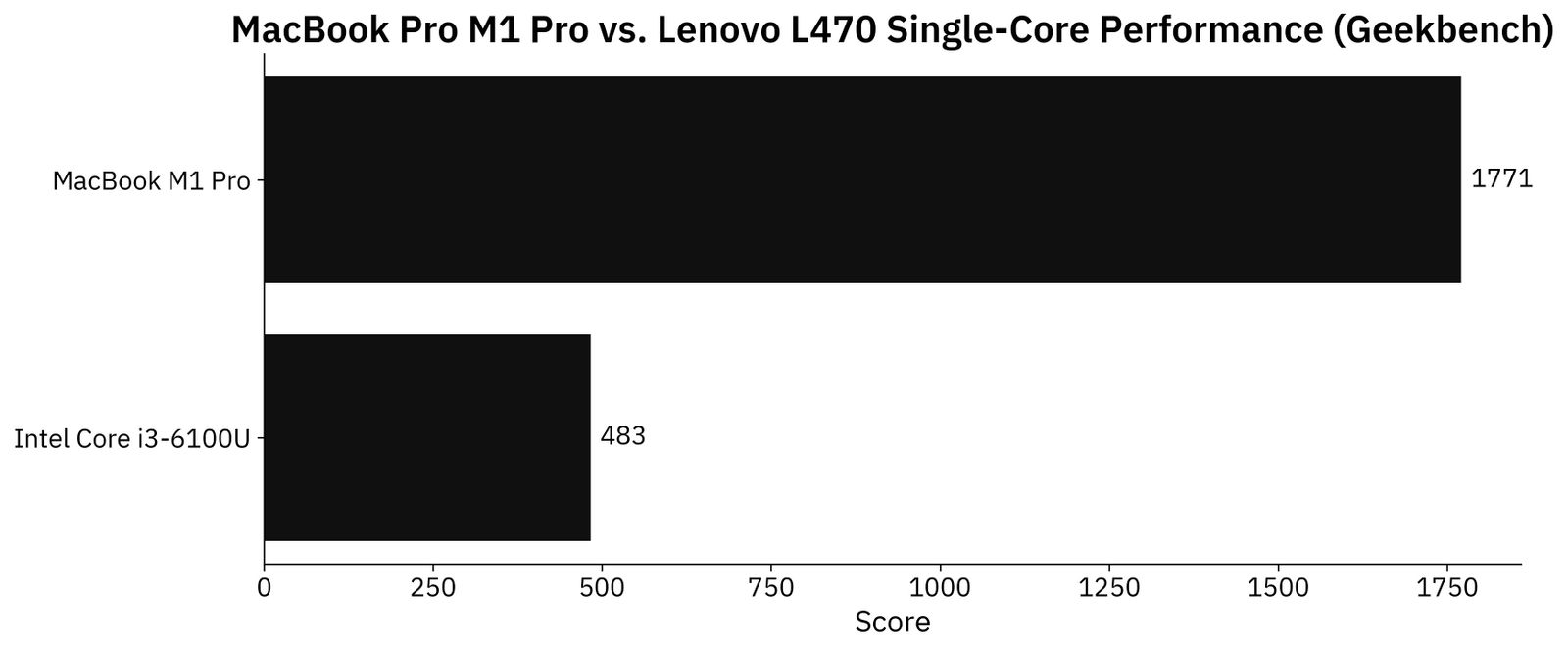
Image 2 - Geekbench single-core performance (image by author)
M1 Pro is about 3.5 times faster, which is expected. Most Windows laptops don’t come close even today, so it’s really not a surprise.
Multicore is where things get interesting. The i3 has only two cores, while M1 Pro has 8 performance and 2 efficiency cores. Here are the results:
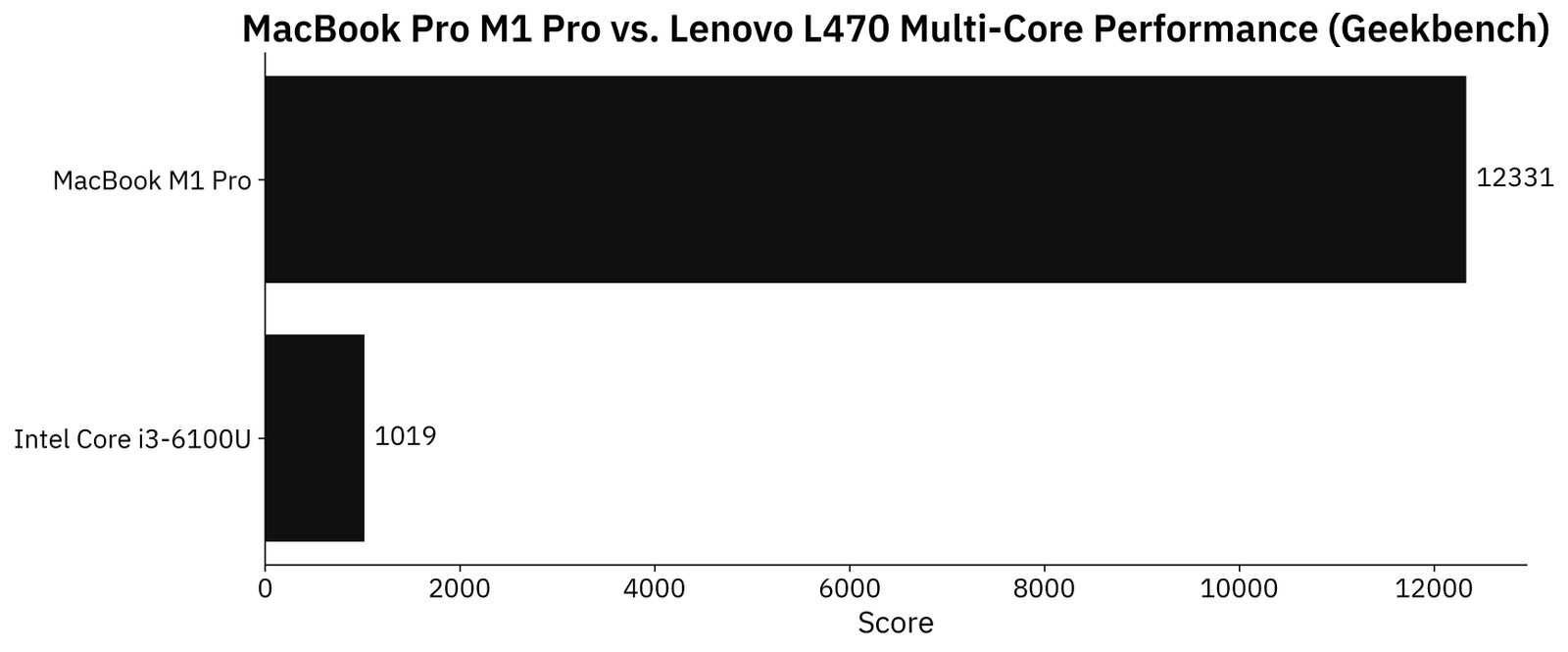
Image 3 - Geekbench multi-core performance (image by author)
As you can see, the Mac came up 12 times faster on this test. That’s a huge difference, and you’ll definitely notice it in everyday use. Also, macOS requires less resources to run smoothly, so that’s another consideration you have to take in mind.
Now let’s get into the actual data science benchmarks, starting with Pandas.
Pandas Benchmark - Typical Data Workflow Times Compared
There’s only so much I can compare in a single article, so let’s stick with the basics. We’ll compare the time required to create, save, read, and transform a Pandas DataFrame.
Create a Pandas DataFrame
Let’s create two datasets - the first one with 1 million rows, and the second one with around 5. These should be enough to push the ThinkPad to its limits.
The code snippet below imports all the libraries needed in this section and also declares a function create_dataset() that, well, creates the datasets.
import random
import string
import numpy as np
import pandas as pd
from datetime import datetime
np.random.seed = 42
def create_dataset(start: datetime, end: datetime, freq: str) -> pd.DataFrame:
def gen_random_string(length: int = 32) -> str:
return ''.join(random.choices(
string.ascii_uppercase + string.digits, k=length)
)
dt = pd.date_range(
start=start,
end=end,
freq=freq, # Increase if you run out of RAM
closed='left'
)
df_size = len(dt)
df = pd.DataFrame({
'date': dt,
'a': np.random.rand(df_size),
'b': np.random.rand(df_size),
'c': np.random.rand(df_size),
'd': np.random.rand(df_size),
'e': np.random.rand(df_size),
'str1': [gen_random_string() for x in range(df_size)],
'str2': [gen_random_string() for x in range(df_size)]
})
return df
Let’s now use it to create both the 1M and 5M datasets:
########## 1M Dataset ##########
df_1m = create_dataset(
start=datetime(2010, 1, 1),
end=datetime(2020, 1, 1),
freq='300s'
)
########## 5M Dataset ##########
df_5m = create_dataset(
start=datetime(2010, 1, 1),
end=datetime(2020, 1, 1),
freq='60s'
)
Here are the times for both laptops and both datasets:
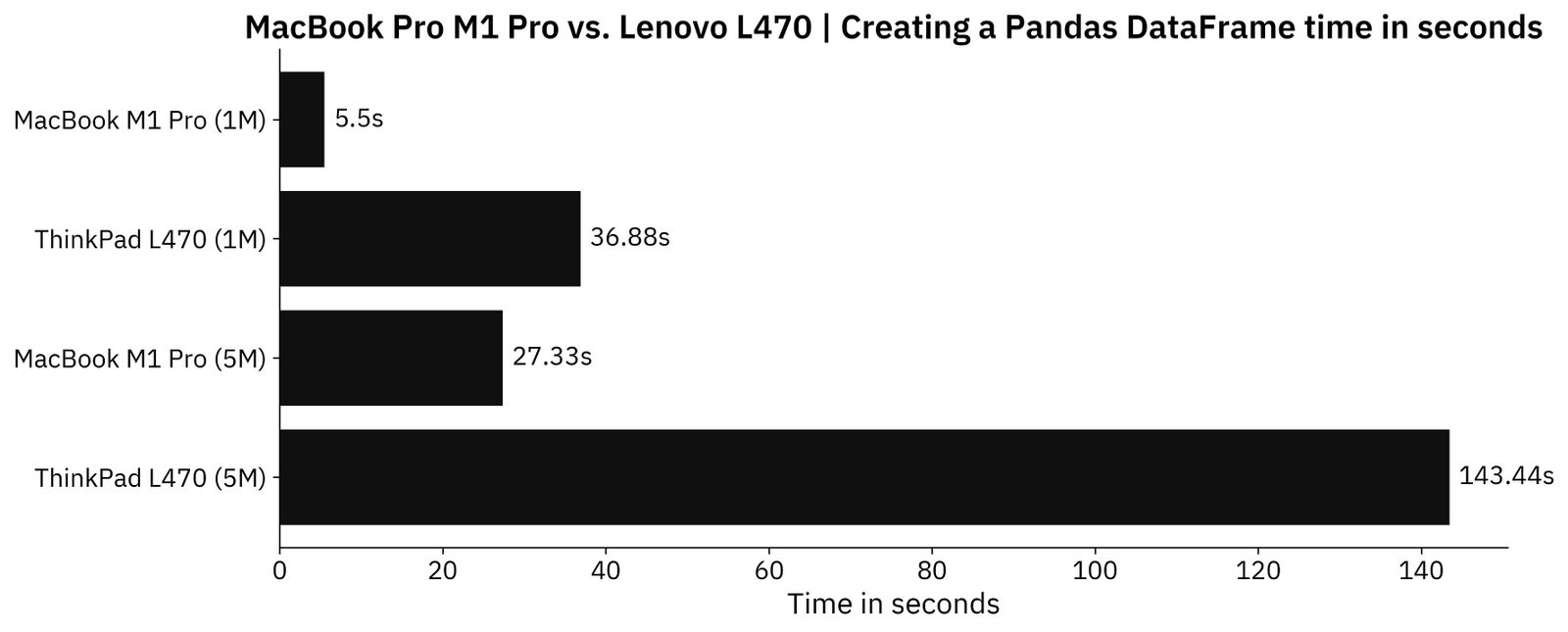
Image 4 - Time needed to create the datasets (image by author)
All things considered, it’s not really that drastic of a difference. The Mac is around 7 times faster for a 1M dataset, and around 5 times faster for a 5M dataset. No crashes or freezes whatsoever occurred on ThinkPad, it just takes more time.
Saving a Dataset to a CSV file
You’ll probably save your data in different states throughout the project, so it would be nice to minimize the time spent here. The code snippet below dumps both Pandas DataFrames to a CSV file:
########## 1M Dataset ##########
df_1m.to_csv("/Users/dradecic/Desktop/1Mdf.csv", index=False)
########## 5M Dataset ##########
df_5m.to_csv("/Users/dradecic/Desktop/5Mdf.csv", index=False)
And here are the results:
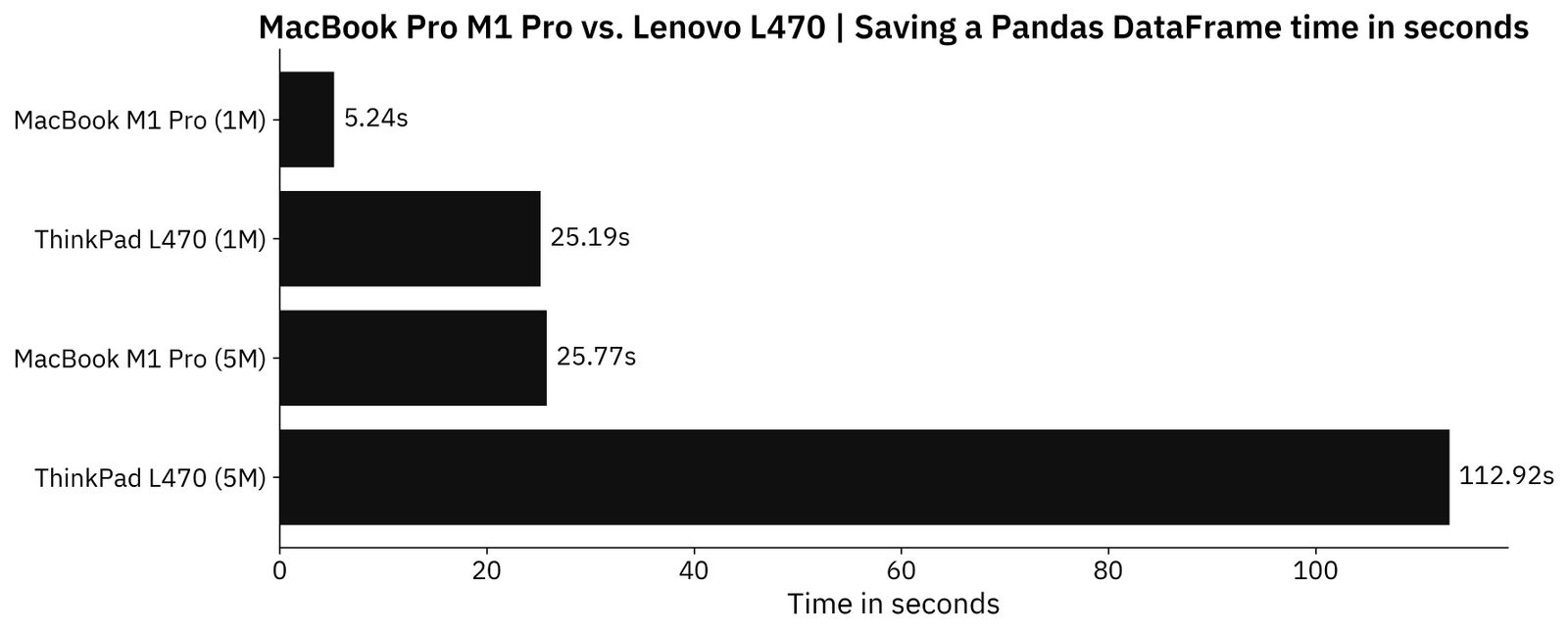
Image 5 - Time needed to save the datasets as CSV files (image by author)
Similar story to what we had earlier. The Mac is around 5 times faster when saving Pandas DataFrame to a CSV file.
Reading a CSV file from a disk
But what about the other way around? Will reading CSV files also be 5 times faster on a Mac? Here’s the code:
########## 1M Dataset ##########
df_1m = pd.read_csv("/Users/dradecic/Desktop/1MDF.csv")
########## 5M Dataset ##########
df_5m = pd.read_csv("/Users/dradecic/Desktop/5MDF.csv")
And the results:
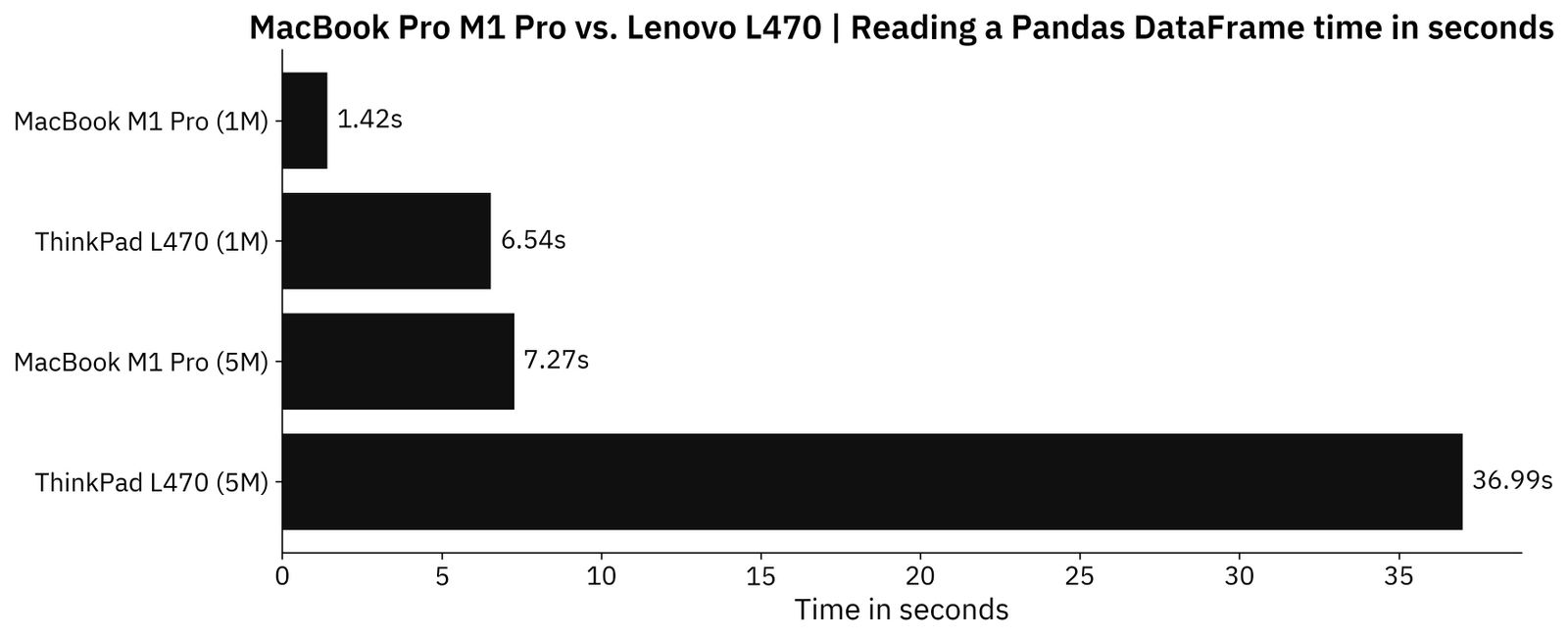
Image 6 - Time needed to read CSV files (image by author)
The 5X time difference seems to be somewhat universal up to this point.
Applying a function to a column
You can apply custom functions on a DataFrame column by calling the apply() method on it. The snippet below reverses the str1 column which initially contains a random string of 32 characters:
def reverse_str(x) -> str:
return x[::-1]
########## 1M Dataset ##########
df_1m['str1_rev'] = df_1m['str1'].apply(reverse_str)
########## 5M Dataset ##########
df_5m['str1_rev'] = df_5m['str1'].apply(reverse_str)
Let’s take a look at the results:
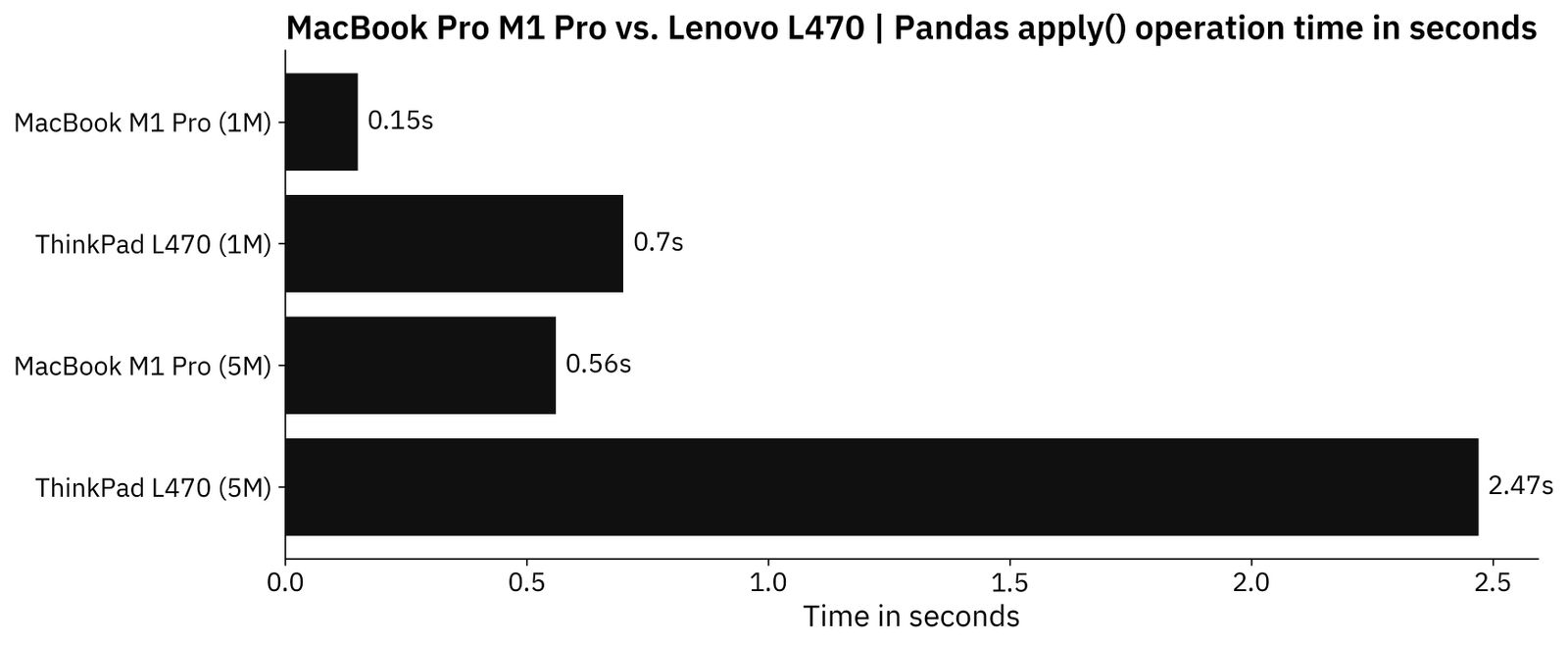
Image 7 - Time needed to reverse a column of strings (image by author)
Once again, there’s around a 5X time difference in favor of the Mac.
To summarize - M1 Pro MacBook is continuously around 5 times faster than ThinkPad L470. It’s not a surprise, but let’s see if TensorFlow can make this difference even bigger.
TensorFlow Benchmark - Custom Model and Transfer Learning
Just to address the elephant in the room - It’s possible to install and even run TensorFlow on i3-6100U, or any other lower-end chip. It will work, but slowly, since the processor isn’t too powerful and there’s no GPU support whatsoever.
For the TensorFlow benchmark, I’ve used the Dogs vs. Cats dataset from Kaggle, which is licensed under the Creative Commons License. Long story short, you can use it for free. As for the dataset preparation, refer to this article if you want to replicate the results.
Let’s dive into the first test.
Custom TensorFlow model
The first TensorFlow benchmark uses data augmentation and applies a two-block convolutional model to the image dataset. There’s nothing special about it, it’s just a model architecture you’re likely to stumble upon when learning TensorFlow:
import os
import warnings
from datetime import datetime
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
warnings.filterwarnings('ignore')
import numpy as np
import tensorflow as tf
tf.random.set_seed(42)
####################
# 1. Data loading
####################
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
train_data = train_datagen.flow_from_directory(
directory='/Users/dradecic/Desktop/data/train/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
valid_data = valid_datagen.flow_from_directory(
directory='/Users/dradecic/Desktop/data/validation/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
####################
# 2. Model
####################
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), input_shape=(224, 224, 3), activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')]
)
####################
# 3. Training
####################
model.fit(
train_data,
validation_data=valid_data,
epochs=5
)
The model was trained for 5 epochs on each machine, and the image below compares the average epoch times:
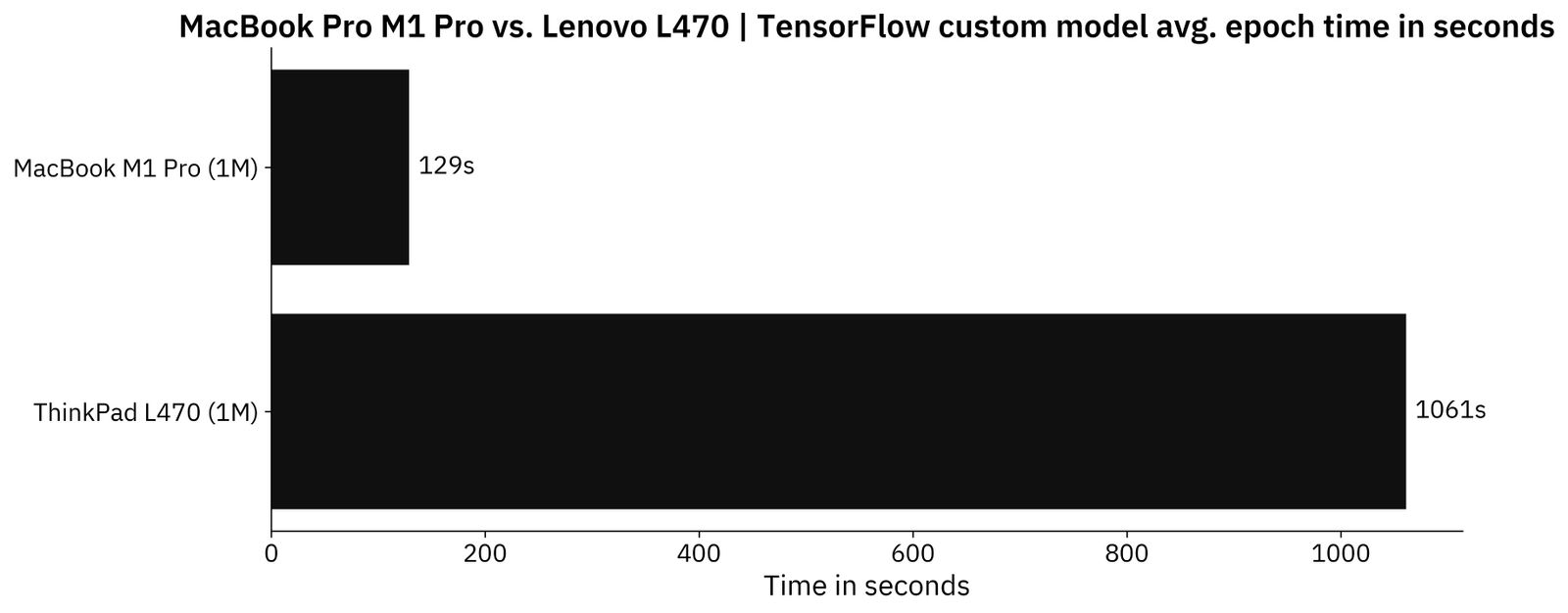
Image 8 - TensorFlow average time per epoch on a custom model (image by author)
As you can see, TensorFlow works on an old laptop but is around 8 times slower when compared to the Mac. Not a deal-breaker if you’re just starting out.
TensorFlow transfer learning model
The code snippet below is more or less identical to the previous one, but with a single important difference - it now uses a pretrained VGG-16 network to classify images:
####################
# 1. Data loading
####################
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
train_data = train_datagen.flow_from_directory(
directory='/Users/dradecic/Desktop/data/train/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
valid_data = valid_datagen.flow_from_directory(
directory='/Users/dradecic/Desktop/data/validation/',
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
####################
# 2. Base model
####################
vgg_base_model = tf.keras.applications.vgg16.VGG16(
include_top=False,
input_shape=(224, 224, 3),
weights='imagenet'
)
for layer in vgg_base_model.layers:
layer.trainable = False
####################
# 3. Custom layers
####################
x = tf.keras.layers.Flatten()(vgg_base_model.layers[-1].output)
x = tf.keras.layers.Dense(128, activation='relu')(x)
out = tf.keras.layers.Dense(2, activation='softmax')(x)
vgg_model = tf.keras.models.Model(
inputs=vgg_base_model.inputs,
outputs=out
)
vgg_model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')]
)
####################
# 4. Training
####################
vgg_model.fit(
train_data,
validation_data=valid_data,
epochs=5
)
The results are much different this time:
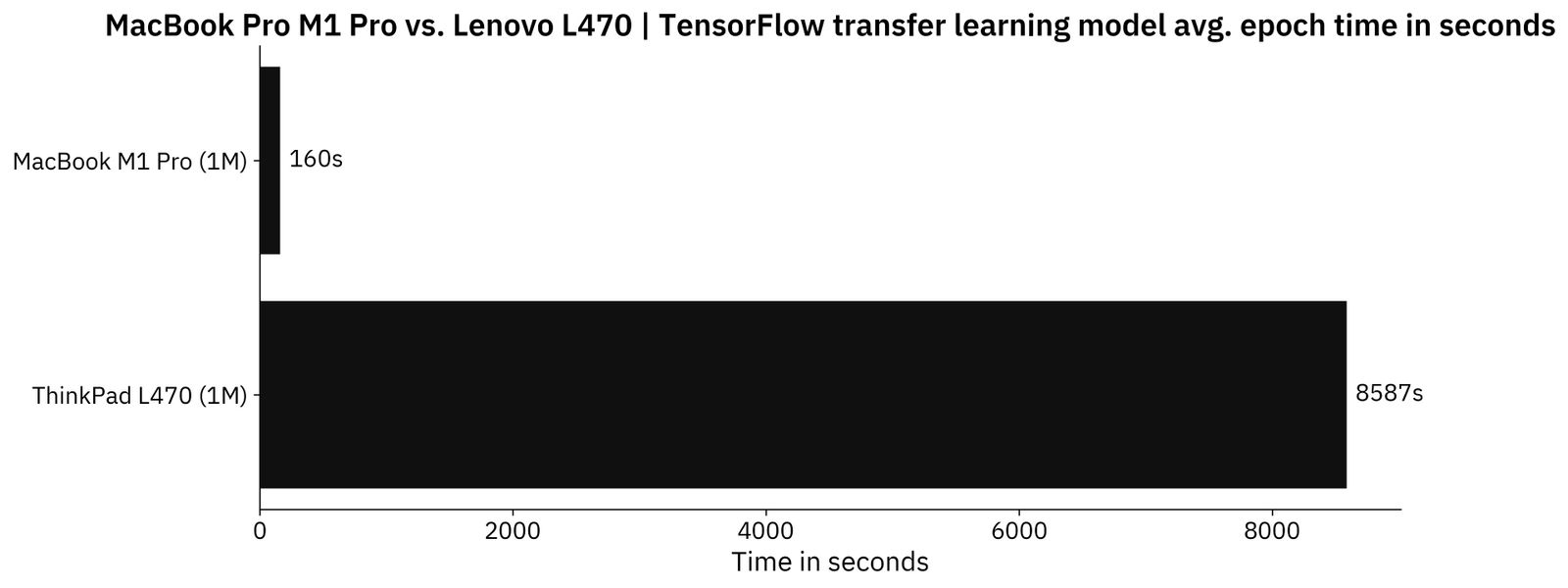
Image 9 - TensorFlow average time per epoch on a transfer learning model (image by author)
As you can see, the average training time per epoch barely increased on the Mac, but it skyrocketed on the ThinkPad. Waiting for the transfer learning model to finish training took a better part of the day on i3-6100U, as it’s almost 54 times slower when compared to the Mac.
So, what have we learned from these benchmarks? Let’s go over some insights next.
Data Science on an Old Laptop - Things to Consider
It’s not impossible to do data wrangling or data science work on an old laptop, especially if you’re just starting out. There are a couple of things you should keep in mind, so let’s go over them.
Old laptop + Deep learning = Google Colab
There’s no reason to put an old laptop through hell just because you’re getting started with deep learning. Google Colab is an amazing pre-configured notebook environment that costs nothing and packs GPU support. If you need more features and longer runtimes, consider Colab Pro.
The lack of ports
It’s weird to say that a Mac has a better port selection, but it’s true in this case. ThinkPad L470 is 5+ years old, so it doesn’t have a USB-C or even an HDMI port. Connecting an external display won’t be so easy.
There’s a VGA port available, but this requires an adapter and compromises in image quality if you have a modern external monitor. Not a deal breaker, just something to consider.
With a Mac, I can connect a 4K external display, monitor light, phone charger, microphone, and headphones - all with a single USB-C cable.
The terrible screen
I’ve never been impressed with ThinkPad displays, but L470 takes the awfulness to a whole different level. The display is 14" which is excellent for a laptop, but not at a 1366x768 resolution. Everything is huge, and you can’t fit more than a window or two onto the screen. The color accuracy is just plain terrible as well.
That wouldn’t be a problem if connecting an external display in full resolution was easier.
On the other side, the Mini LED screen on Mac spans across 16" and packs a resolution of 3456x2234. It’s a night and day difference, to say at least.
Conclusion
Intel’s i3-6100U can handle Pandas pretty well, and it can also train deep learning models with TensorFlow, albeit slowly. You can definitely get into data science and even work professionally in the industry while using it. Most of the work nowadays is done in the cloud, so laptops boil down to being glorified keyboards anyway.
The biggest issue of a cheap and old laptop, when compared to something new, isn’t in the raw performance, but in other compromises instead. Looking at a terrible screen for 8+ hours a day, and dealing with a poor battery and a whole lot of cables isn’t fun.
But on the other hand, if you want to get into data science and have $200 to spare, an old laptop will do just fine.
What do you think of this old-vs-new laptop comparison? Are you currently using a laptop that has seen better days? If so, what issues are you battling with daily? Let me know in the comment section below.
More benchmarks
- MacBook M1 vs. M1 Pro
- MacBook M1 vs. Google Colab
- MacBook M1 Pro vs. Google Colab
- MacBook M1 vs. RTX3060Ti
Stay connected
- Hire me as a technical writer
- Subscribe on YouTube
- Connect on LinkedIn