
Your go-to guide for optimizing feed-forward neural network models on any dataset
Deep learning boils down to experimentation. Training hundreds of models by hand is tedious and time-consuming. I’d rather do something else with my time, and I imagine the same holds for you.
Picture this — you want to find the optimal architecture for your deep neural network. Where do you start? How many layers? How many nodes per layer? What about the activation functions? There are just too many moving parts.
You can automate this process to a degree, and this article will show you how. After reading, you’ll have one function for generating neural network architectures given specific parameters and the other one for finding the optimal architecture.
Don’t feel like reading? Watch my video instead:
You can download the source code on GitHub.
Dataset used and data preprocessing
I don’t plan to spend much time here. We’ll use the same dataset as in the previous article— the wine quality dataset from Kaggle:
Image 1 — Wine quality dataset from Kaggle (image by author)
You can use the following code to import it to Python and print a random couple of rows:
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import itertools
import warnings
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
tf.random.set_seed(42)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
warnings.filterwarnings('ignore')
df = pd.read_csv('data/winequalityN.csv')
df.sample(5)
We’re ignoring the warnings and changing the default TensorFlow log level just so we don’t get overwhelmed with the output.
Here’s how the dataset looks like:

Image 2 — A random sample of the wine quality dataset (image by author)
The dataset is mostly clean, but isn’t designed for binary classification by default (good/bad wine). Instead, the wines are rated on a scale. We’ll address that now, with numerous other things:
- Delete missing values— There’s only a handful of them, so we won’t waste time on imputation.
- Handle categorical features— The only one is
type, indicating whether the wine is white or red. - Convert to a binary classification task— We’ll declare any wine with a grade of 6 and above as good, and anything below as bad.
- Train/test split— A classic 80:20 split.
- Scale the data— The scale between predictors differs significantly, so we’ll use the
StandardScalerto bring the values closer.
Here’s the entire data preprocessing code snippet:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Prepare the data
df = df.dropna()
df['is_white_wine'] = [1 if typ == 'white' else 0 for typ in df['type']]
df['is_good_wine'] = [1 if quality >= 6 else 0 for quality in df['quality']]
df.drop(['type', 'quality'], axis=1, inplace=True)
# Train/test split
X = df.drop('is_good_wine', axis=1)
y = df['is_good_wine']
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2, random_state=42
)
# Scaling
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Once again, please refer to the previous article if you want more detailed insights into the logic behind data preprocessing.
With that out of the way, let’s see how to approach optimizing neural network architectures.
How to approach optimizing neural network models?
The approach to finding the optimal neural network model will have some tweakable constants. Today’s network will have 3 hidden layers, with a minimum of 64 and a maximum of 256 nodes per layer. We’ll set the step size between nodes to 64, so the possibilities are 64, 128, 192, and 256:
num_layers = 3
min_nodes_per_layer = 64
max_nodes_per_layer = 256
node_step_size = 64
Let’s verify the node number possibilities. You can do so by creating a list of ranges between the minimum and maximum number of nodes, having the step size in mind:
node_options = list(range(
min_nodes_per_layer,
max_nodes_per_layer + 1,
node_step_size
))
Here’s what you’ll see:
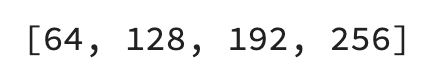
Image 3 — Node number possibilities (image by author)
Taking this logic to two hidden layers, you end up with the following possibilities:
two_layer_possibilities = [node_options, node_options]
Or visually:
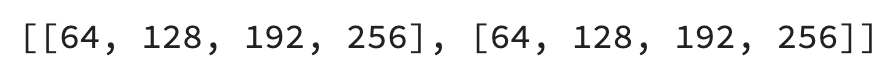
Image 4 — Node number possibilities for two hidden layers (image by author)
To get every possible permutation of the options among two layers, you can use the product() function from itertools:
list(itertools.product(*two_layer_possibilities))
Here’s the output:

Image 5 — Two layer deep neural network architecture permutations (image by author)
The goal is to optimize a 3-layer-deep neural network, so we’ll end up with a bit more permutations. You can declare the possibilities by first multiplying the list of node options with num_layers and then calculate the permutations:
layer_possibilities = [node_options] * num_layers
layer_node_permutations = list(itertools.product(*layer_possibilities))
It’s a lot of options — 64 in total. During optimization, we’ll iterate over the permutations and then iterate again over the values of the individual permutation to get the node counts for each hidden layer.
In short, we’ll have two for loops. Here’s the logic for the first two permutations:
for permutation in layer_node_permutations[:2]:
for nodes_at_layer in permutation:
print(nodes_at_layer)
print()
The second print statement is here just to make a gap between models, so don’t think too much of it. Here’s the output:

Image 6 — Number of nodes at each layer (image by author)
We’ll create a new tf.keras.Sequential model at each iteration and add a tf.keras.layers.InputLayer to it with a shape of a single training row ((12,)). Then, we’ll iterate over the items in a single permutation and add a tf.keras.layers.Dense layer to the model with the number of nodes set to the current value of the single permutation. Finally, we’ll add a tf.keras.layers.Dense output layer.
It’s a good idea to set the name to the model, so it’s easier to compare them later. We’ll hardcode the input shape and the activation functions for no, and set these parts as dynamic in the next section.
Here’s the code:
models = []
for permutation in layer_node_permutations:
model = tf.keras.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape=(12,)))
model_name = ''
for nodes_at_layer in permutation:
model.add(tf.keras.layers.Dense(nodes_at_layer, activation='relu'))
model_name += f'dense{nodes_at_layer}_'
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model._name = model_name[:-1]
models.append(model)
And now let’s inspect how a single model looks like:
models[0].summary()

Image 7 — Single model architecture (image by author)
That’s the logic we’ll go with. There’s a way to improve it, though, as it’s not convenient to run dozens of notebook cells every time you want to run the optimization. It’s also not the best idea to hardcode values for activation functions, input shape, and so on.
For that reason, we’ll declare a function for generating Sequential models next.
Model generation function for optimizing neural networks
The function accepts a lot of parameters but doesn’t contain anything we didn’t cover previously. It gives you the option to change the input shape, activation function for the hidden and output layer, and the number of nodes at the output layer.
Here’s the code:
def get_models(num_layers: int,
min_nodes_per_layer: int,
max_nodes_per_layer: int,
node_step_size: int,
input_shape: tuple,
hidden_layer_activation: str = 'relu',
num_nodes_at_output: int = 1,
output_layer_activation: str = 'sigmoid') -> list:
node_options = list(range(min_nodes_per_layer, max_nodes_per_layer + 1, node_step_size))
layer_possibilities = [node_options] * num_layers
layer_node_permutations = list(itertools.product(*layer_possibilities))
models = []
for permutation in layer_node_permutations:
model = tf.keras.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape=input_shape))
model_name = ''
for nodes_at_layer in permutation:
model.add(tf.keras.layers.Dense(nodes_at_layer, activation=hidden_layer_activation))
model_name += f'dense{nodes_at_layer}_'
model.add(tf.keras.layers.Dense(num_nodes_at_output, activation=output_layer_activation))
model._name = model_name[:-1]
models.append(model)
return models
Let’s test it — we’ll stick to a model with three hidden layers, each having a minimum of 64 and a maximum of 256 nodes:
all_models = get_models(
num_layers=3,
min_nodes_per_layer=64,
max_nodes_per_layer=256,
node_step_size=64,
input_shape=(12,)
)
Feel free to inspect the values of the all_models list. It contains 64 Sequential models, each having a unique name and architecture. Training so many models will take time, so let’s make things extra simple by writing yet another helper function.
Model training function for optimizing neural networks
This one accepts the list of models, training and testing data, and optionally a number of epochs and the verbosity level. It’s advised to set verbosity to 0, so you don’t get overwhelmed with the console output. The function returns a Pandas DataFrame containing the performance metrics on the test set, measured in accuracy, precision, recall, and F1.
Here’s the code:
def optimize(models: list,
X_train: np.array,
y_train: np.array,
X_test: np.array,
y_test: np.array,
epochs: int = 50,
verbose: int = 0) -> pd.DataFrame:
# We'll store the results here
results = []
def train(model: tf.keras.Sequential) -> dict:
# Change this however you want
# We're not optimizing this part today
model.compile(
loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[
tf.keras.metrics.BinaryAccuracy(name='accuracy')
]
)
# Train the model
model.fit(
X_train,
y_train,
epochs=epochs,
verbose=verbose
)
# Make predictions on the test set
preds = model.predict(X_test)
prediction_classes = [1 if prob > 0.5 else 0 for prob in np.ravel(preds)]
# Return evaluation metrics on the test set
return {
'model_name': model.name,
'test_accuracy': accuracy_score(y_test, prediction_classes),
'test_precision': precision_score(y_test, prediction_classes),
'test_recall': recall_score(y_test, prediction_classes),
'test_f1': f1_score(y_test, prediction_classes)
}
# Train every model and save results
for model in models:
try:
print(model.name, end=' ... ')
res = train(model=model)
results.append(res)
except Exception as e:
print(f'{model.name} --> {str(e)}')
return pd.DataFrame(results)
And now, let’s finally start the optimization.
Running the optimization
Keep in mind — the optimization will take some time, as we’re training 64 models for 50 epochs. Here’s how to start the process:
optimization_results = optimize(
models=all_models,
X_train=X_train_scaled,
y_train=y_train,
X_test=X_test_scaled,
y_test=y_test
)
The optimization ran for 34 minutes on my machine (M1 MacBook Pro) and printed the following:
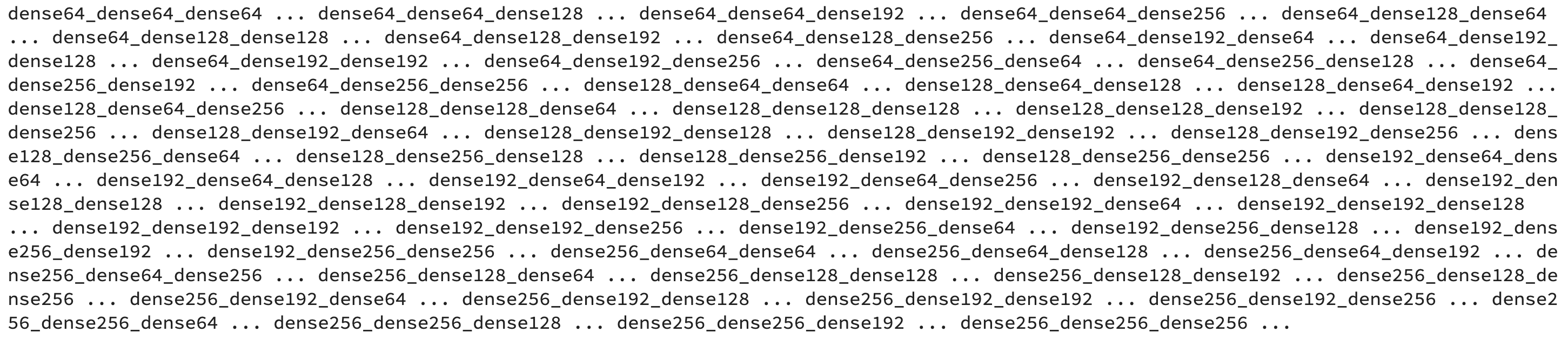
Image 8 — Optimization output (image by author)
You’re seeing this output because of the print() statement in the optimize() function. It’s there to give you a sense of the progress.
We now have a DataFrame we can sort either by accuracy, precision, recall, or F1. Here’s how to sort it by accuracy in descending order, so the model with the highest value is displayed first:
optimization_results.sort_values(by='test_accuracy', ascending=False)
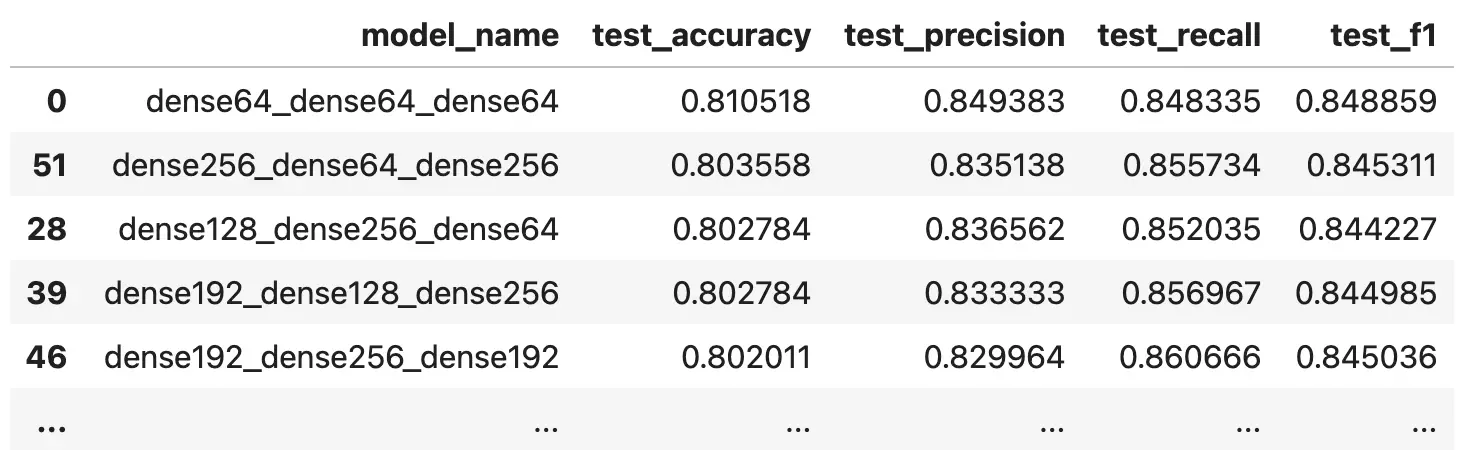
Image 9 — Model optimization results (image by author)
It looks like the simplest model resulted in the best accuracy. You could also test the optimization for models with two and four hidden layers, or even more, but I’ll leave that up to you. It’s just a matter of calling the get_models() function and passing in different parameter values.
And that’s all I wanted to cover today. Let’s wrap things up next.
Parting words
Finding an optimal neural network architecture for your dataset boils down to one thing and one thing only — experimentation. It’s quite tedious to train and evaluate hundreds of models by hand, so the two functions you’ve seen today can save you some time. You still need to wait for the models to train, but the entire process is fast on this dataset.
A good way to proceed from here is to pick an architecture you find best and tune the learning rate.
Things get a lot more complicated and the training times get longer if you’re dealing with image data and convolutional layers. That’s what the next article will cover — we’ll start diving into computer vision and train a simple convolutional neural network. Don’t worry, it won’t be on the MNIST dataset.
How do you approach optimizing feed-forward neural networks? Is it something similar, or are you using a dedicated AutoML library? Please let me know in the comment section below.
Stay connected
- Sign up for my newsletter
- Subscribe on YouTube
- Connect on LinkedIn