
Part 5/6 - Visualize gradient ranges of a Strava route with Python and Plotly
It’s been quite a while since the last article in the cycling series, I know. The good news is - the story continues today. We’ll continue where we left off, and that’s gradient analysis and visualization. By now you know what gradients in cycling are, and how to calculate gradients as an elevation difference between two points.
Today we’ll visualize gradient ranges, which means showing how much time and distance was covered in a particular gradient range, for example, between 3% and 5%. In the upcoming article, we’ll include that visualization (and others) in an interactive Python dashboard.
Don’t feel like reading? Watch my video instead:
You can download the source code on GitHub.
How to Read a Strava Route Dataset
We won’t bother with the GPX route file today, as we already have a CSV file that contains data points, elevation, distance, and gradient data. To start, we’ll import Numpy, Pandas, and Plotly, and then we’ll read the dataset:
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import plotly.offline as pyo
route_df = pd.read_csv('../data/route_df_gradient.csv')
route_df.head()
Here’s what it looks like:
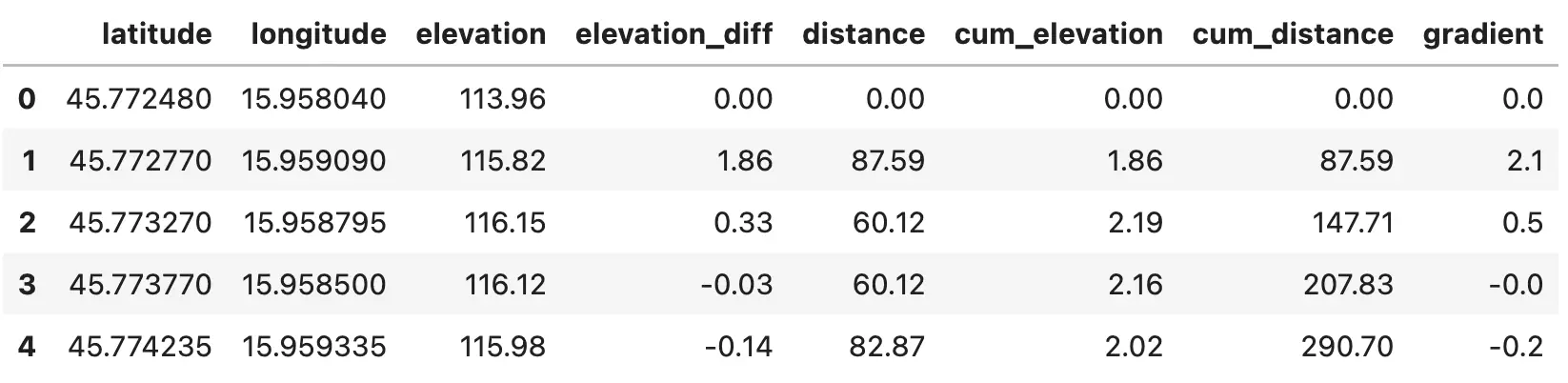
Image 1 - Strava route dataset with distance, elevation, and gradient data (image by author)
We’re particularly interested in the gradient column. To start the analysis, let’s call the describe() method on it:
route_df['gradient'].describe()
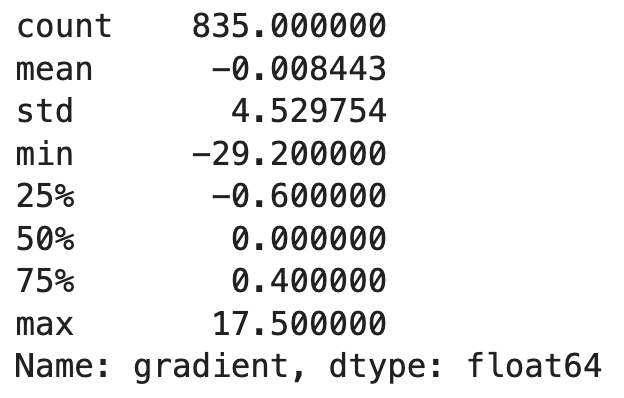
Image 2 - Gradient statistics (image by author)
The route looks mostly flat (mean and median), with a minimum gradient of -29.2% and a maximum gradient of 17.5%. These are the key information we need for the next step - creating intervals (bins) for gradient ranges.
How to Create Intervals with Pandas
We’ll now group gradient values into bins. That way we can calculate statistics for every gradient range - for example, for all data points captured on a 3-5% gradient. To do so, we’ll use the IntervalIndex class from Pandas. It allows us to create bins from tuples.
The values used in the interval index below are completely random. You’re free to use different ones to accommodate your route file. The bins are also left-closed, which means the value on the left is included, but the one on the right isn’t:
bins = pd.IntervalIndex.from_tuples([
(-30, -10),
(-10, -5),
(-5, -3),
(-3, -1),
(-1, 0),
(0, 1),
(1, 3),
(3, 5),
(5, 7),
(7, 10),
(10, 12),
(12, 15),
(15, 20)
], closed='left')
bins
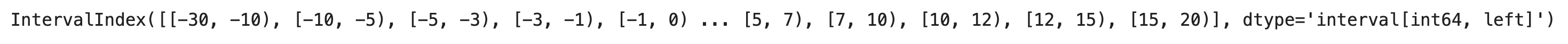
Image 3 - Bins for the gradient ranges (image by author)
Let’s now add these bins to the dataset by using the cut() method from Pandas:
route_df['gradient_range'] = pd.cut(route_df['gradient'], bins=bins)
route_df.head()
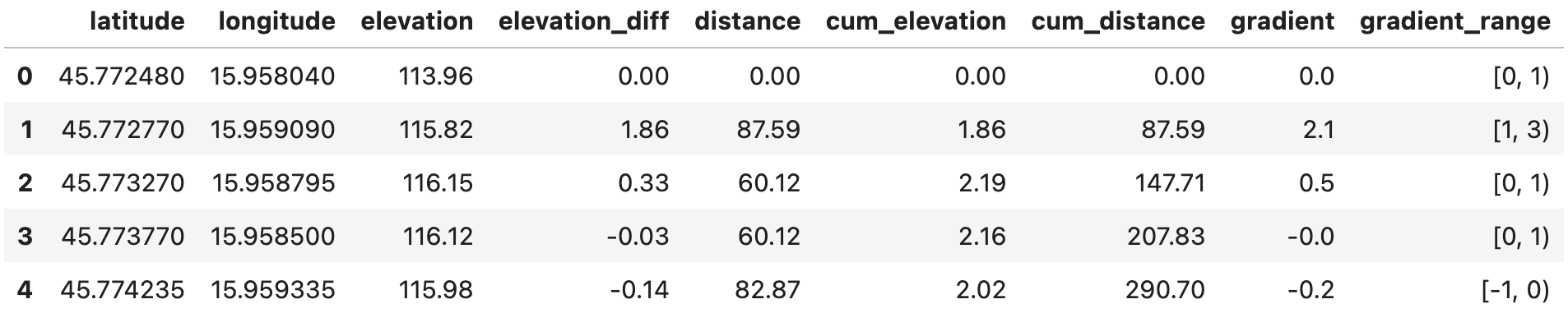
Image 4 - DataFrame with gradient ranges added (image by author)
We now have 13 distinct groups stored in the gradient_range columns. As the next step, we’ll calculate a couple of statistics from it that will be useful for visualization.
Calculate Statistics from Gradient Ranges
The goal now is to create a new DataFrame that will contain statistics for each gradient, including:
- Distance traveled
- Percentage of the ride spent in this gradient range
- Elevation gained
- Elevation lost
We’ll create it by iterating over each unique gradient range and subsetting the dataset - and calculating statistics from there:
gradient_details = []
# For each unique gradient range
for gr_range in route_df['gradient_range'].unique():
# Keep that subset only
subset = route_df[route_df['gradient_range'] == gr_range]
# Statistics
total_distance = subset['distance'].sum()
pct_of_total_ride = (subset['distance'].sum() / route_df['distance'].sum()) * 100
elevation_gain = subset[subset['elevation_diff'] > 0]['elevation_diff'].sum()
elevation_lost = subset[subset['elevation_diff'] < 0]['elevation_diff'].sum()
# Save results
gradient_details.append({
'gradient_range': gr_range,
'total_distance': np.round(total_distance, 2),
'pct_of_total_ride': np.round(pct_of_total_ride, 2),
'elevation_gain': np.round(elevation_gain, 2),
'elevation_lost': np.round(np.abs(elevation_lost), 2)
})
Once done, convert the list to the DataFrame and sort it by the gradient range. It’s an IntervalIndex, which means sorting works like a charm:
gradient_details_df = pd.DataFrame(gradient_details).sort_values(by='gradient_range').reset_index(drop=True)
gradient_details_df
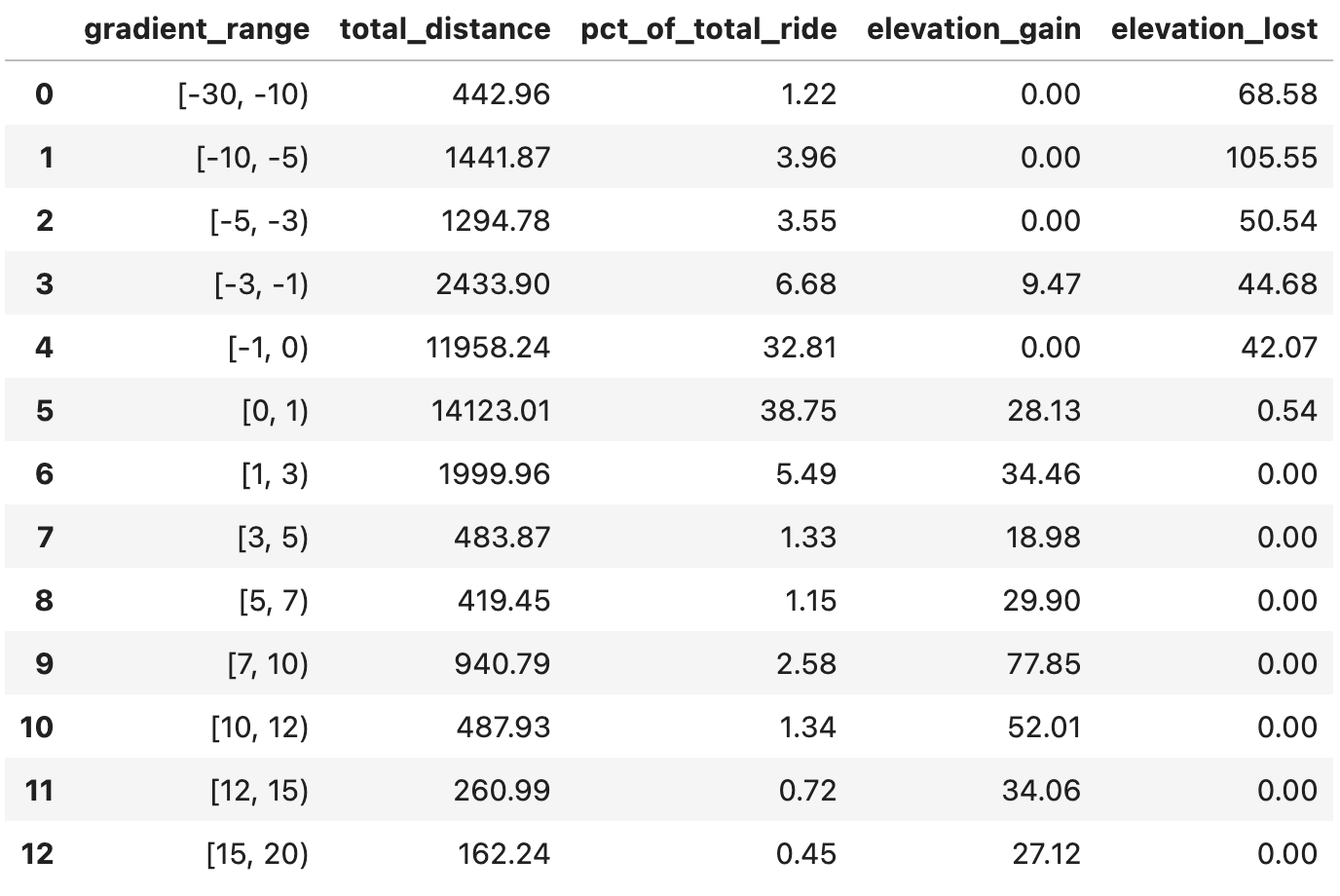
Image 5 - Statistics for each gradient range (image by author)
Here are a couple of interpretations:
- I’ve covered 442.96 meters in a gradient range of [-30%, -10%), and lost 68.58 meters of elevation along the way.
- Most of the ride is flat [-1%, 1) - 71,56% of the route or 26 kilometers.
- I’ve ridden only 911 meters on gradients of 10% and above.
Let’s now visualize this data.
Visualize Strava Gradient Ranges with Plotly
I’ve decided to use Plotly for visualizing data because it produces interactive charts by default. You’re free to stick with Matplotlib or any other library.
To start, let’s declare a list of colors for each gradient range - going from blue to red (descent to ascent):
colors = [
'#0d46a0', '#2f3e9e', '#2195f2', '#4fc2f7',
'#a5d6a7', '#66bb6a', '#fff59d', '#ffee58',
'#ffca28', '#ffa000', '#ff6f00', '#f4511e', '#bf360c'
]
We’ll make a bar chart, and each bar will display a gradient range and distance traveled in kilometers. Each bar will also show the range and the distance traveled. Feel free to convert the values to miles if you’re using the Imperial system:
custom_text = [f'''<b>{gr}%</b> - {dst}km''' for gr, dst in zip(
gradient_details_df['gradient_range'].astype('str'),
gradient_details_df['total_distance'].apply(lambda x: round(x / 1000, 2))
)]

Image 6 - Text for individual bars (image by author)
And finally, we’ll create the figure:
fig = go.Figure(
data=[go.Bar(
x=gradient_details_df['gradient_range'].astype(str),
y=gradient_details_df['total_distance'].apply(lambda x: round(x / 1000, 2)),
marker_color=colors,
text=custom_text
)],
layout=go.Layout(
bargap=0,
title='Gradient profile of a route',
xaxis_title='Gradient range (%)',
yaxis_title='Distance covered (km)',
autosize=False,
width=1440,
height=800,
template='simple_white'
)
)
fig.show()
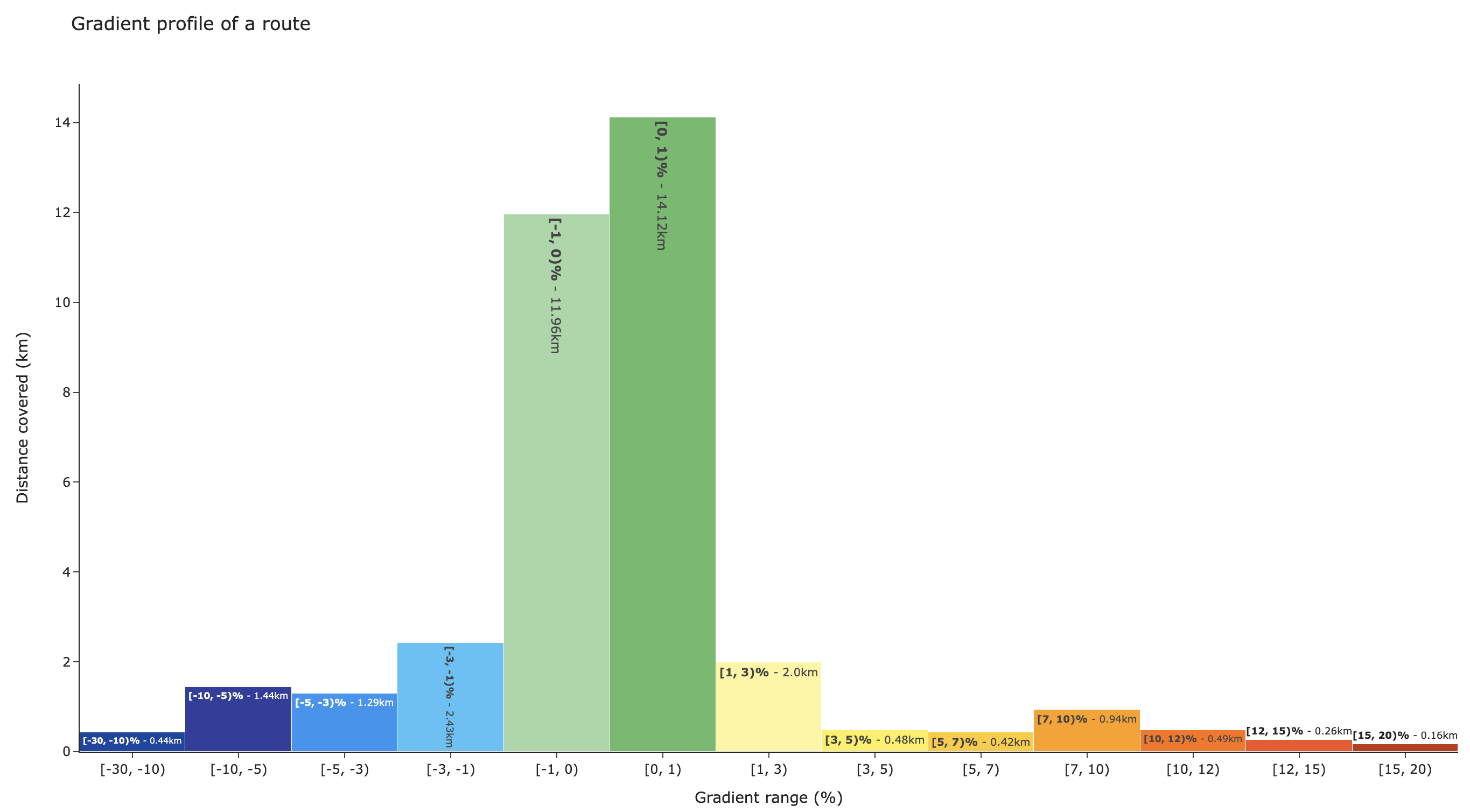
Image 7 - Bar chart of gradient ranges (image by author)
We can see that most of the ride is green, which indicates a flat surface. There are only 2.3 kilometers of climbing on grades of 5% and above. It doesn’t sound like a lot, but my legs and lungs wouldn’t agree at the time.
Conclusion
And there you have it - how to visualize gradient ranges of a Strava GPX route file. I don’t think the end goal was clear from the start, as the term “gradient range” can mean pretty much anything. I hope you can understand my vision of the term after reading, and that you’ll find it useful when analyzing your Strava workouts.
In the following article, we’ll combine everything covered so far in the series and much more on an interactive Python dashboard, so stay tuned for that.