
Learn to count words of a book and address the common stop word issue - implemented in PySpark
Do you know what’s the most common beginner exercise in Apache Spark? You’ve guessed it - it’s word counts. The idea is to grab a text document, preferably a long one, and count the occurrences of each word. It’s a typical MapReduce task you can tackle with Spark’s RDDs. Today you’ll learn how to solve it, and how to solve it well.
We’ll go over three solutions:
- Basic solution - Counts words with Spark’s
countByValue()method. It’s okay for beginners, but not an optimal solution. - MapReduce with regular expressions - All text is not created equal. Words “Python”, “python”, and “python,” are identical to you and me, but not to Spark.
- MapReduce with NLTK - Takes the whole thing to a new level by filtering out common English stop words. We don’t care how many times “the” occurs, it’s useless information.
We have a lot of work to do, so let’s get started right away.
Don’t feel like reading? I’ve covered the same topic in video format:
Dataset Used for Word Count in Spark
I’ve used this free eBook from Project Gutenberg called Millions From Waste. I’ve never read it, but it seems long enough for what we want to do. Download the TXT version - Right click - Save as - millions_from_waste.txt:
Image 1 - Millions From Waste book (image by author)
Make sure you know the absolute path to the text file before proceeding.
Simple Word Count with Spark and Python
As with any Spark application, the first thing you’ll need to do is create a new Spark session. Use the following code to create a local session named word-counts:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("word-counts")
sc = SparkContext(conf=conf)
From here, load the dataset from a text file and convert it into an RDD by using the textFile() method:
book = sc.textFile("file:///Users/dradecic/Desktop/millions_from_waste.txt")
book.collect()[:10]
The collect() method prints the entire RDD - [:10] makes sure only the first ten rows are printed. Let’s see what we’re dealing with:

Image 2 - First 10 rows of the book (image by author)
Each line of the text document is a dedicated element of a Spark RDD file. Since each line is a string, we can split it to get individual words and call countByValue() to get the word counts:
word_counts = book.flatMap(lambda x: x.split()).countByValue()
for i, (word, count) in enumerate(word_counts.items()):
if i == 15: break
print(word, count)

Image 3 - Simple word count in PySpark (image by author)
Is that it? Well, no. We have the word counts, but as of now, Spark makes the distinction between lowercase and uppercase letters and punctuations. We also have a lot of stop words here, such as “The”, “of”, “A”, “is”, and so on. We’ll address the uppercases and punctuation next, and leave stop words for later.
Word Counts with Regular Expressions in PySpark
Regular expressions allow us to specify a searchable pattern, and replace any occurrence in a string with something else. Our goal is to lowercase each word and remove punctuation. Two functions will assist us here:
preprocess_word()- Applies a regular expression to a single word (removes punctuation) and lowercases it.preprocess_words()- Appliespreprocess_word()to a sequence of words passed in as a string.
The definition for these functions and usage example is shown below:
import re
def preprocess_word(word: str):
return re.sub("[^A-Za-z0-9]+", "", word.lower())
def preprocess_words(words: str):
return [preprocess_word(word) for word in words.split()]
preprocess_words("The Project Gutenberg eBook of Millions from Waste, by Frederick A.")

Image 4 - Preprocessed sentence of the book (image by author)
Just what we wanted - all words are lowercased and punctuation is removed. Let’s calculate the word counts in the same way:
book = sc.textFile("file:///Users/dradecic/Desktop/millions_from_waste.txt")
word_counts = book.flatMap(preprocess_words).countByValue()
for i, (word, count) in enumerate(word_counts.items()):
if i == 15: break
print(word, count)

Image 5 - Word counts with preprocessed input (image by author)
There’s another way to count words that will make sorting much easier. You’ll have to:
- Add counts to the input word - go from
(x)to(x, 1)for starters. - Apply a reducer method to sum the counts:
book = sc.textFile("file:///Users/dradecic/Desktop/millions_from_waste.txt")
words = book.flatMap(preprocess_words)
word_counts = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
word_counts.collect()[:10]

Image 6 - Reformatted word counts (image by author)
Spark comes with a method called sortByKey() that is used, well, for sorting. The only problem is, the key is currently the word and not the count. Reverse words and counts using the following code:
word_counts_sorted = word_counts.map(lambda x: (x[1], x[0]))
word_counts_sorted.collect()[:10]

Image 7 - Sorting word counts (1) (image by author)
And now, finally, sort the RDD by the key:
word_counts_sorted = word_counts.map(lambda x: (x[1], x[0])).sortByKey()
word_counts_sorted.collect()[:10]

Image 8 - Sorting word counts (2) (image by author)
Words get sorted by count in ascending order, which is not what we want. The first argument of sortByKey() is ascending, and it’s set to True by default. Flip it to False to get words sorted by count in descending order:
word_counts_sorted = word_counts.map(lambda x: (x[1], x[0])).sortByKey(False)
word_counts_sorted.collect()[:10]

Image 9 - Sorting word counts (3) (image by author)
Now that works, but we have another problem. All the most frequently occurring words are stop words, and from them, we can’t guess what the book is all about. In the next section, we’ll use the NLTK module to get rid of them.
Remove Stop Words from Word Counts with NLTK
If you haven’t worked with NLTK yet, you’ll have to install the library and download the stop words. Run the following code line by line straight from the Notebook:
!pip install nltk
import nltk
nltk.download("stopwords")
Once that’s done, import the stopwords module and print the first few from the English language:
from nltk.corpus import stopwords
stop_words = stopwords.words("english")
stop_words[:10]
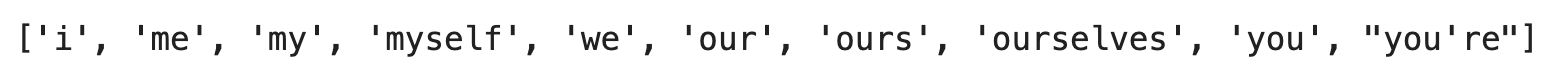
Image 10 - First 10 English stop words (image by author)
So, what’s next? We’ll want to modify the preprocess_words() function to exclude the stop words. Add another line to it so only words that aren’t an empty string and stop words are kept:
def preprocess_word(word: str):
return re.sub("[^A-Za-z0-9]+", "", word.lower())
def preprocess_words(words: str):
preprocessed = [preprocess_word(word) for word in words.split()]
return [word for word in preprocessed if word not in stop_words and word != ""]
preprocess_words("The Project Gutenberg eBook of Millions from Waste, by Frederick A.")
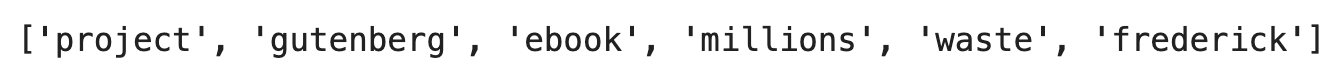
Image 11 - First book sentence without stop words (image by author)
Much cleaner output this time. We don’t get any gibberish as the last time. The only step remaining is to calculate and sort word counts again. The code is the same as before:
book = sc.textFile("file:///Users/dradecic/Desktop/millions_from_waste.txt")
words = book.flatMap(preprocess_words)
word_counts = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
word_counts_sorted = word_counts.map(lambda x: (x[1], x[0])).sortByKey(False)
word_counts_sorted.collect()[:10]

Image 12 - Word counts in Spark without stop words (image by author)
We’ve only printed the top 10 words, but you get the point - the output is much cleaner this time. Feel free to explore other words, and maybe even display their frequencies on a chart.
Summary of Word Counts in Apache Spark
Today you’ve learned how to solve the most popular MapReduce problem with Python and Spark using only the RDD syntax. The entire thing is stupidly simple, but you can (and should) enrich the solution by preprocessing each word and excluding the most common ones.
Up next, we’ll dive deep into SparkSQL, so stay tuned!
Recommended reads
- 5 Best Books to Learn Data Science Prerequisites (Math, Stats, and Programming)
- Top 5 Books to Learn Data Science in 2022
- 7 Ways to Print a List in Python
Stay connected
- Hire me as a technical writer
- Subscribe on YouTube
- Connect on LinkedIn