
Download any file from Amazon S3 (AWS) with a couple of lines of Python code
By now, you know how to upload local files to Amazon S3 with Apache Airflow. But how can you go the other way around? Is there an easy way to download files from Amazon S3? There definitely is, and you’ll learn all about it today. After reading, you’ll know how to download any file from S3 through Apache Airflow, and how to control its path and name.
Reading the previous article is recommended, as we won’t go over the S3 bucket and configuration setup again. Make sure you have a bucket created and at least one file uploaded to it. a
Don’t feel like reading? Watch my video instead:
Configure an S3 Bucket and Airflow Connection
As mentioned in the introduction section, you should have an S3 bucket configured and at least one file uploaded to it. Here’s mine bds-airflow-bucket with a single posts.json file:
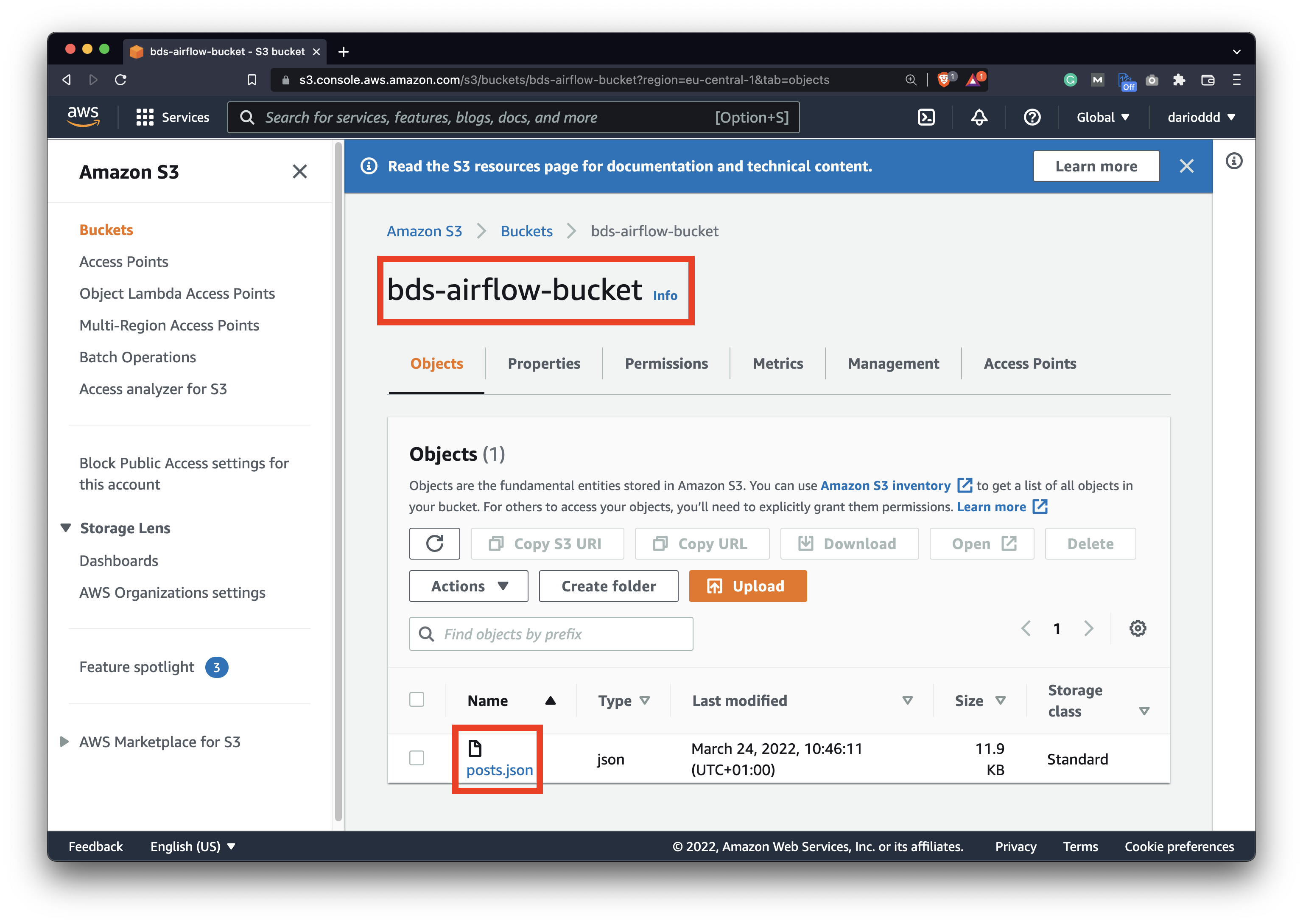
Image 1 - Amazon S3 bucket with a single object stored (image by author)
Also, on the Airflow webserver home page, you should have an S3 connection configured. You can find it under Admin - Connections. Make sure to configure it as follows:
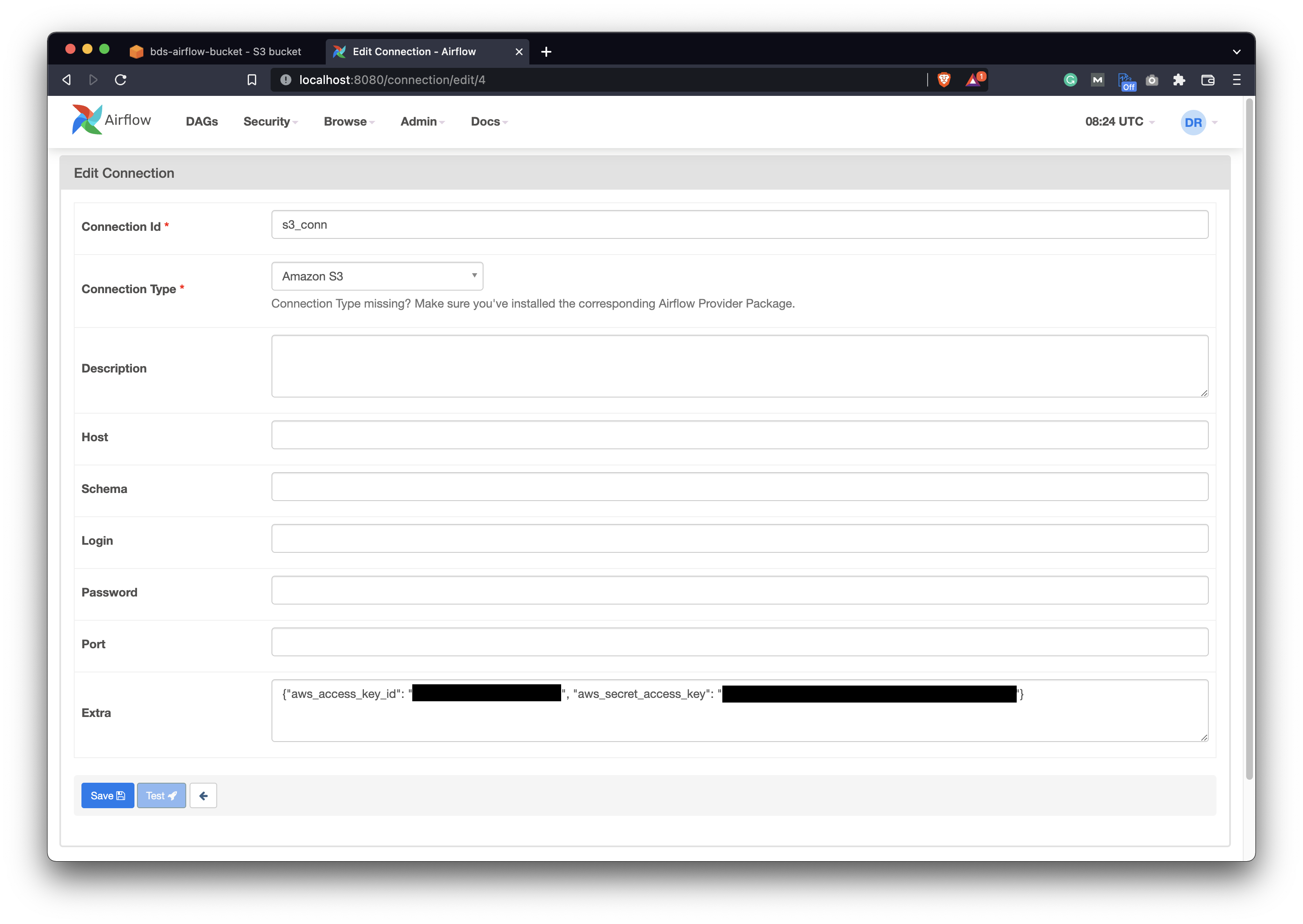
Image 2 - Airflow Amazon S3 connection (image by author)
That’s all we need to download a file from an S3 bucket, so let’s do that next.
Write the Airflow DAG
Create a new Python file in ~/airflow/dags folder. I’ve named mine s3_download.py. We’ll start with the library imports and the DAG boilerplate code. As before, you’ll need the S3Hook class to communicate with the S3 bucket:
import os
from datetime import datetime
from airflow.models import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
with DAG(
dag_id='s3_download',
schedule_interval='@daily',
start_date=datetime(2022, 3, 1),
catchup=False
) as dag:
pass
Downloading a file boils down to declaring a PythonOperator based task. It will call the download_from_s3() function which accepts three parameters:
key- string, the name/path of the file on S3. For example,posts.jsonwill grab that file from the root of the bucket. You can also specify paths, such as/data/posts/posts.json. Make sure to match your case.bucket_name- string, name of the bucket you want to download the file from.local_path- string, a directory to which the file will be saved. Note it’s a directory path, not a file path.
The same function first creates an instance of the S3Hook class and uses the connection established earlier. Then, it calls the download_file() method of the hook instance to, well, download the file.
The function returns a string, which is an absolute path to the file downloaded from S3. Make sure to return it, as you’ll need it later:
import os
...
def download_from_s3(key: str, bucket_name: str, local_path: str) -> str:
hook = S3Hook('s3_conn')
file_name = hook.download_file(key=key, bucket_name=bucket_name, local_path=local_path)
return file_name
with DAG(...) as dag:
# Download a file
task_download_from_s3 = PythonOperator(
task_id='download_from_s3',
python_callable=download_from_s3,
op_kwargs={
'key': 'posts.json',
'bucket_name': 'bds-airflow-bucket',
'local_path': '/Users/dradecic/airflow/data/'
}
)
Here’s the problem - S3Hook downloads a file to the local_path folder and gives it an arbitrary name without any extension. We don’t want that, so we’ll declare another task that renames the file.
It grabs the absolute path from Airflow XComs, removes the file name, and appends new_name to it:
import os
...
def download_from_s3(key: str, bucket_name: str, local_path: str) -> str:
...
def rename_file(ti, new_name: str) -> None:
downloaded_file_name = ti.xcom_pull(task_ids=['download_from_s3'])
downloaded_file_path = '/'.join(downloaded_file_name[0].split('/')[:-1])
os.rename(src=downloaded_file_name[0], dst=f"{downloaded_file_path}/{new_name}")
with DAG(...) as dag:
# Download a file
task_download_from_s3 = PythonOperator(...)
# Rename the file
task_rename_file = PythonOperator(
task_id='rename_file',
python_callable=rename_file,
op_kwargs={
'new_name': 's3_downloaded_posts.json'
}
)
task_download_from_s3 >> task_rename_file
Let’s test them both now.
First, we’ll have to download the file from S3:
airflow tasks test s3_download download_from_s3 2022-3-1
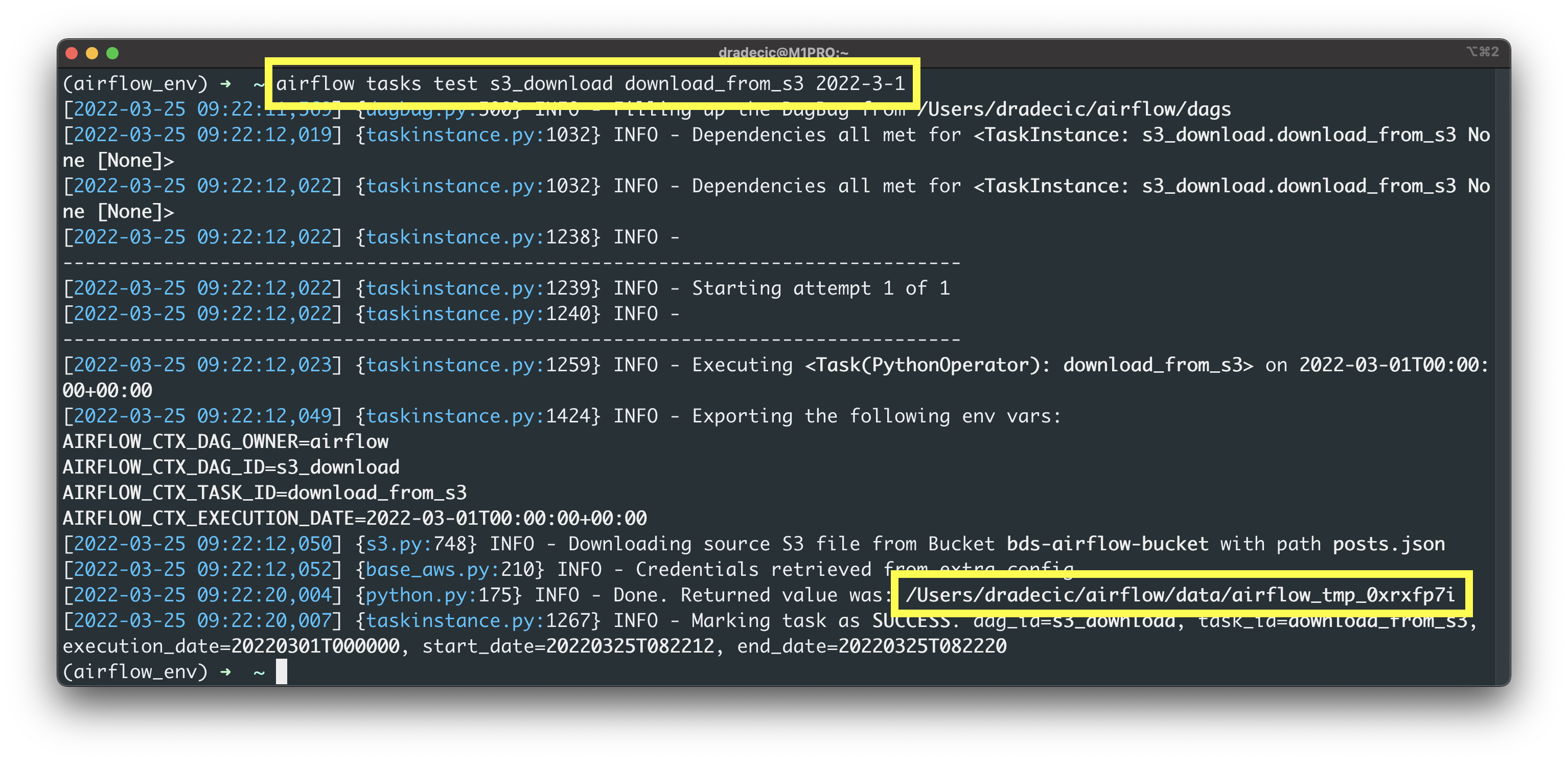
Image 3 - Testing the download_from_s3 task (image by author)
As you can see, Airflow saved the file from S3 to /Users/dradecic/airflow/data/airflow_tmp_0xrx7pyi, which is a completely random file name.
The second task is here to rename it to s3_downloaded_posts.json:
airflow tasks test s3_download rename_file 2022-3-1
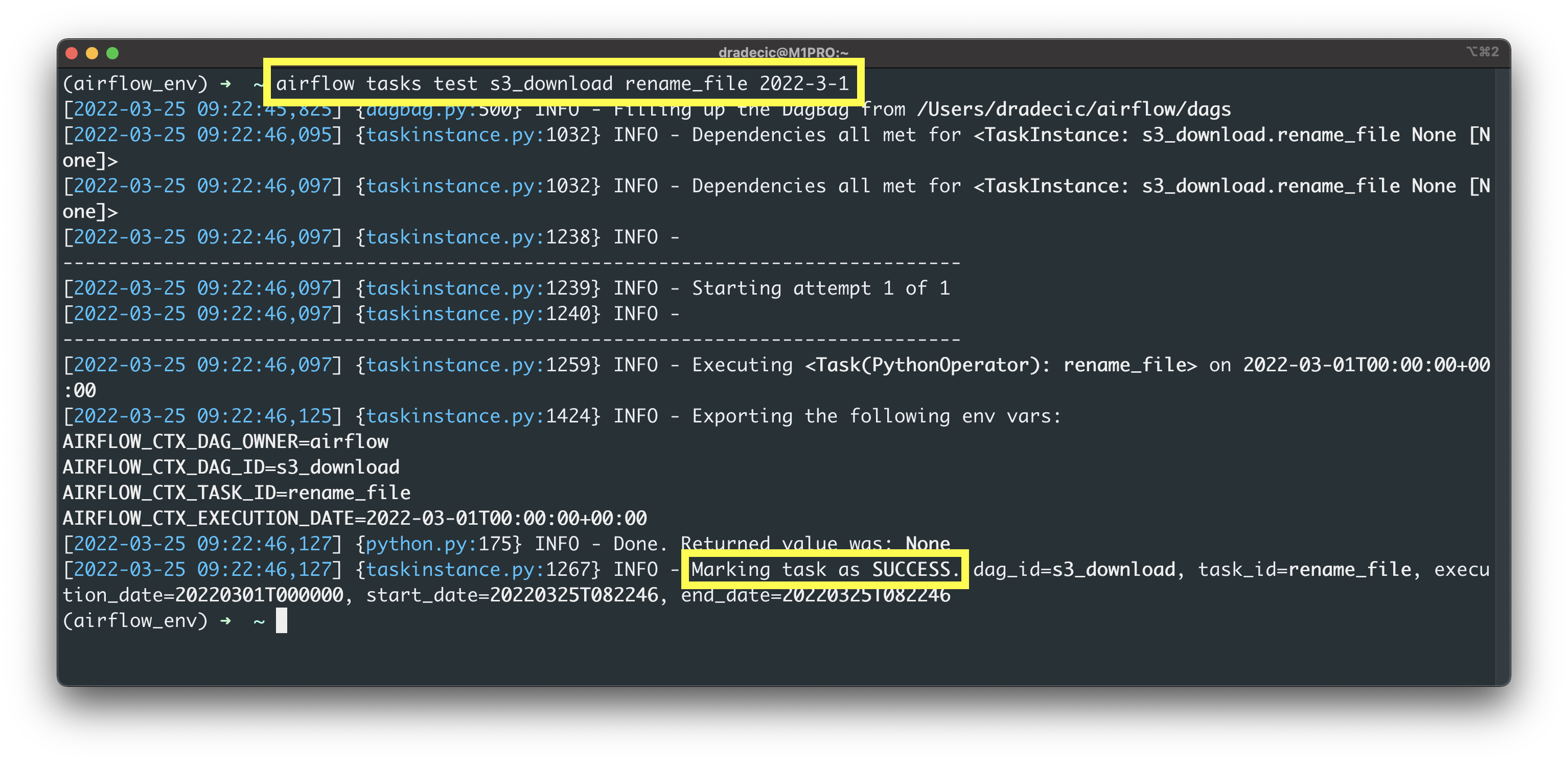
Image 4 - Testing the rename_file task (image by author)
The task finished successfully, which means we should see the file in the data folder:
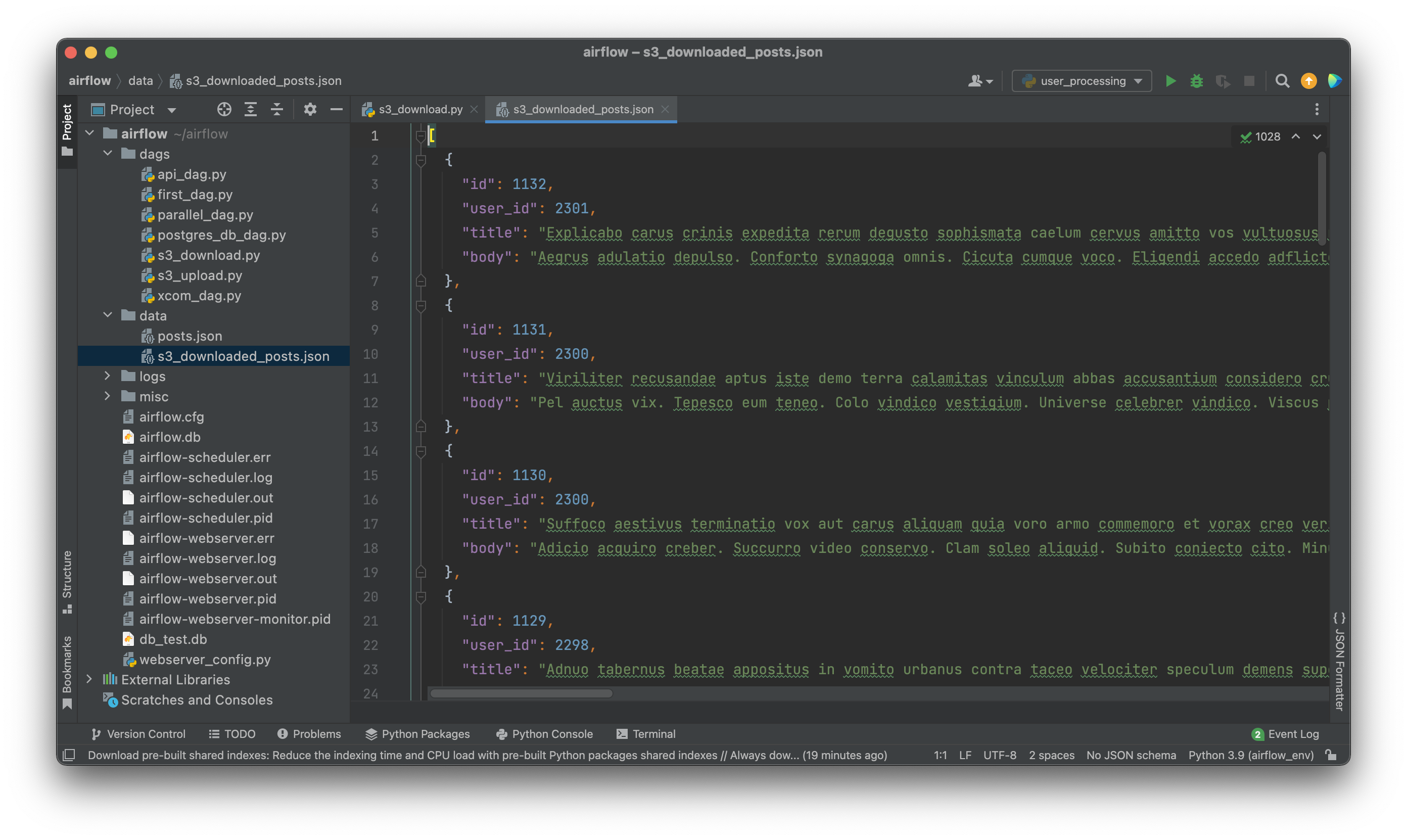
Image 5 - Contents of the downloaded file (image by author)
Aaaand done! We have the entire DAG coded out and tested. Let’s make a short recap before finishing off this article.
Conclusion
Downloading files from Amazon S3 with Airflow is as easy as uploading them. It all boils down to a single function call - either load_file() or download_file(). You now know how to do both, and also how to tackle potential issues that may come up.
Stay tuned to the upcoming articles in the Apache Airflow series.
Recommended reads
- 5 Best Books to Learn Data Science Prerequisites (Math, Stats, and Programming)
- Top 5 Books to Learn Data Science in 2022
- How to Install Apache Airflow Locally
Stay connected
- Hire me as a technical writer
- Subscribe on YouTube
- Connect on LinkedIn