
Yes, SQL can do that now.
Time series forecasting is a task I usually do with Python. You might be accustomed to other languages, such as R or Julia, but I bet never crossed your mind for this type of task. If that’s the case — keep reading — you’ll be surprised by how much can be accomplished with SQL only.
Time series are different than your average machine learning task. You can’t train the model once, and use it for months in production. Time series models must be trained with the entirety of history data, and new data points might come every hour, day, week, or month — varying from project to project.
That’s why doing the training process in-database can be beneficial, if hardware resources are limited. Python will almost always consume more resources than the database.
We’ll use Oracle Cloud once again. It’s free, so please register and create an instance of the OLTP database (Version 19c, has 0.2TB of storage). Once done, download the cloud wallet and establish a connection through SQL Developer— or any other tool.
This will take you 10 minutes at least but is a fairly straightforward thing to do, so I won’t waste time on it.
Awesome! Let’s continue with the data loading.
Data loading
We need some data before any type of forecasting can be done. A de facto standard dataset for any time series tutorial is the Airline passengers dataset. Download it, and keep it somewhere safe for a minute.
We need to create a table that will hold the dataset, so let’s do that next. Here’s the SQL statement:
CREATE TABLE airline_passengers(
air_period DATE,
air_passengers INTEGER
);
We can now load in the dataset via the Import Data functionality:
Image by author
When a modal window pops-up simply provide a path to the downloaded CSV and click Next a couple of times. Choose columns using your best judgment, and select date format as YYYY-MM.
Once done, our dataset is ready to use:
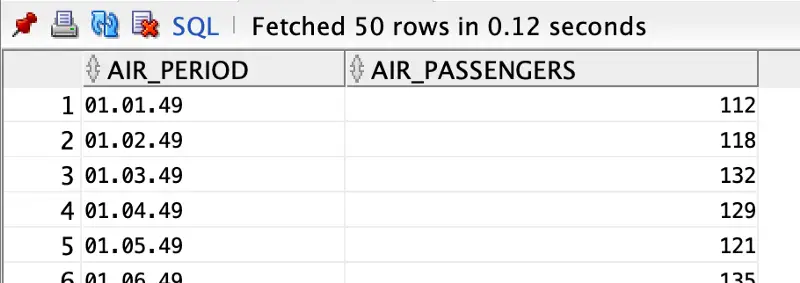
Image by author
Awesome! We can now continue with the model training and forecasting.
Model training
Our dataset has 144 rows. We won’t perform the model training on the entirety of it. We’ll keep the last 12 rows for the evaluation.
To start with the training, we need to create a VIEW that points to the training data. Here’s how:
CREATE OR REPLACE VIEW src_passengers AS
SELECT * FROM airline_passengers
WHERE air_period < TO_DATE('1960-01-01', 'YYYY-MM-DD');
The src_passengers view now holds the first 132 rows - just what we want.
Next, we’ll declare a short PL/SQL snippet that handles the model training:
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst(DBMS_DATA_MINING.ALGO_NAME) := DBMS_DATA_MINING.ALGO_EXPONENTIAL_SMOOTHING;
v_setlst(DBMS_DATA_MINING.EXSM_INTERVAL) := DBMS_DATA_MINING.EXSM_INTERVAL_MONTH;
v_setlst(DBMS_DATA_MINING.EXSM_PREDICTION_STEP) := '12';
v_setlst(DBMS_DATA_MINING.EXSM_MODEL) := DBMS_DATA_MINING.EXSM_HW;
v_setlst(DBMS_DATA_MINING.EXSM_SEASONALITY) := '12';
DBMS_DATA_MINING.CREATE_MODEL2(
model_name => 'AIRLINE_PSG_FORECAST',
mining_function => 'TIME_SERIES',
data_query => 'SELECT * FROM src_passengers',
set_list => v_setlst,
case_id_column_name => 'air_period',
target_column_name => 'air_passengers'
);
END;
/
Let’s break the snippet down to make it easier to understand:
DBMS_DATA_MINING.ALGO_NAME- type of time series forecasting algorithms, exponential smoothing is the only one available currentlyDBMS_DATA_MINING.EXSM_INTERVAL- indicates the interval of the dataset. Our data is stored in monthly intervals, hence theEXSM_INTERVAL_MONTHvalueDBMS_DATA_MINING.PREDICTION_STEP- how many predictions to make. 12 (one year) is goodDBMS_DATA_MINING.EXSM_MODEL- essentially a hyperparameter combination for an exponential smoothing model. I’ve chosen to use triple exponential smoothing or Holt-Winters. Here’s the complete list of available algorithms.DBMS_DATA_MINING.EXSM_SEASONALITY- indicates how long a single season lasts for
Once that is declared, we can create a time series model with the help of a DBMS_DATA_MINING.CREATE_MODEL2 procedure (great naming convention by the way). Here are the explanations:
model_name- arbitrary, name the model as you wishmining_function- set toTIME_SERIES, it’s quite clear whydata_query- how can the model get to the training dataset_list- list of setting declared earlier, tells Oracle how to actually train the modelcase_id_column_name- name of the column that contains date valuestarget_column_name- name of the column that contains numeric values (what we’re trying to predict)
And that’s it! If you can understand this, you know how to train time series models with SQL.
You can now run the PL/SQL snippet. It will take a couple of seconds to finish. Once done you can proceed to the next section.
Model evaluation
Let’s see how good our model performed. I’ve prepared the following statement for that:
SELECT
a.case_id AS time_period,
b.air_passengers AS actual,
ROUND(a.prediction, 2) AS predicted,
ROUND((b.air_passengers - a.prediction), 2) AS difference,
ROUND((ABS(b.air_passengers - a.prediction) / b.air_passengers) * 100, 2) AS pct_error
FROM
dm$p0airline_psg_forecast a,
airline_passengers b
WHERE
a.case_id = b.air_period
AND a.case_id >= TO_DATE('1960-01-01', 'YYYY-MM-DD');
It compares actual data with the predictions made by the Holt-Winters algorithm and also compares the error in absolute and percentage terms. Here’s the output of the above SQL statement:
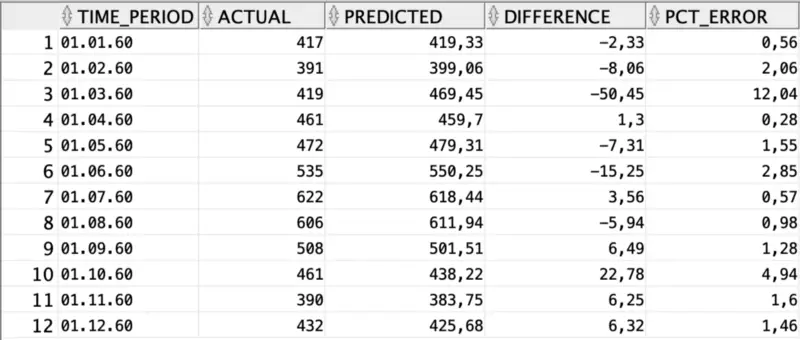
Image by author
Awesome! Our model isn’t that bad for the work we’ve put in. Let’s wrap things up in the next section.
Before you go
This was a lot of work — no arguing there. Still, there are ways we could improve. One idea pops into mind immediately — make a function that will return the best algorithm.
You could do so by storing all possible algorithms in an array, and then train a model while iterating through the array, keeping track of the performance for every model. But that’s a topic for another time.
Thanks for reading.