
Essential guide to multiprocessing with Python.
Executing tasks sequentially might not be a good idea. If the input to the second task isn’t an output of the first task, you’re wasting both time and CPU.
As you probably know, Python’s <em>Global Interpreter Lock</em> __ (GIL) mechanism allows only one thread to execute Python bytecode at once. It’s a severe limitation you can avoid by changing the Python interpreter or implementing process-based parallelism techniques.
Today you’ll learn how to execute tasks in parallel with Python with the concurrent.futures library. You’ll understand the concept with a hands-on example – fetching data from multiple API endpoints.
You can download the source code for this article here.
Problem description
The goal is to connect to jsonplaceholder.typicode.com— a free fake REST API.
You’ll connect to several endpoints and obtain data in the JSON format. There’ll be six endpoints in total. Not a whole lot, and Python will most likely complete the task in a second or so. Not too great for demonstrating multiprocessing capabilities, so we’ll spice things up a bit.
In addition to fetching API data, the program will also sleep for a second between making requests. As there are six endpoints, the program should do nothing for six seconds — but only when the calls are executed sequentially.
Let’s test the execution time without parallelism first.
Test: Running tasks sequentially
Let’s take a look at the entire script and break it down:
import time
import requests
URLS = [
'https://jsonplaceholder.typicode.com/posts',
'https://jsonplaceholder.typicode.com/comments',
'https://jsonplaceholder.typicode.com/albums',
'https://jsonplaceholder.typicode.com/photos',
'https://jsonplaceholder.typicode.com/todos',
'https://jsonplaceholder.typicode.com/users'
]
def fetch_single(url: str) -> None:
print(f'Fetching: {url}...')
requests.get(url)
time.sleep(1)
print(f'Fetched {url}!')
if __name__ == '__main__':
time_start = time.time()
for url in URLS:
fetch_single(url)
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
There’s a list of API endpoints stored in the URLS variable. You’ll fetch the data from there. Below it, you’ll find the fetch_single() function. It makes a GET request to a specific URL and sleeps for a second. It also prints when fetching started and finished.
The script takes note of the start and finish time and subtracts them to get the total execution time. The fetch_single() function is called on every URL from the URLS variable.
You’ll get the following output in the console once you run this script:
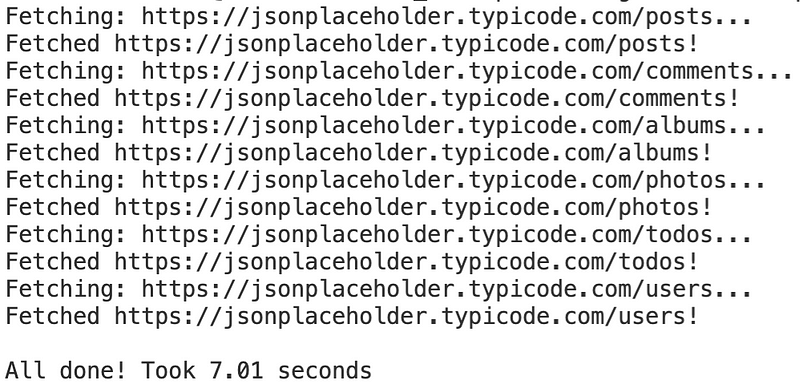
Image 1 — Without multiprocessing script output (image by author)
That’s sequential execution in a nutshell. The script took around 7 seconds to finish on my machine. You’ll likely get near identical results.
Let’s see how to reduce execution time with parallelism next.
Test: Running tasks in parallel
Let’s take a look at the script to see what’s changed:
import time
import requests
import concurrent.futures
URLS = [
'https://jsonplaceholder.typicode.com/posts',
'https://jsonplaceholder.typicode.com/comments',
'https://jsonplaceholder.typicode.com/albums',
'https://jsonplaceholder.typicode.com/photos',
'https://jsonplaceholder.typicode.com/todos',
'https://jsonplaceholder.typicode.com/users'
]
def fetch_single(url: str) -> None:
print(f'Fetching: {url}...')
requests.get(url)
time.sleep(1)
print(f'Fetched {url}!')
if __name__ == '__main__':
time_start = time.time()
with concurrent.futures.ProcessPoolExecutor() as ppe:
for url in URLS:
ppe.submit(fetch_single, url)
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
The concurrent.futures library is used to implement process-based parallelism. Both URLS and fetch_single() are identical, so there’s no need to go over them again.
Down below is where things get interesting. You’ll have to use the ProcessPoolExecutor class. According to the documentation, it’s a class that uses a pool of processes to execute calls asynchronously [1].
The with statement is here to ensure everything gets cleaned up properly after the task finishes.
You can use the submit() function to pass the tasks you want to be executed in parallel. The first argument is the function name (make sure not to call it), and the second one is for the URL parameter.
You’ll get the following output in the console once you run this script:
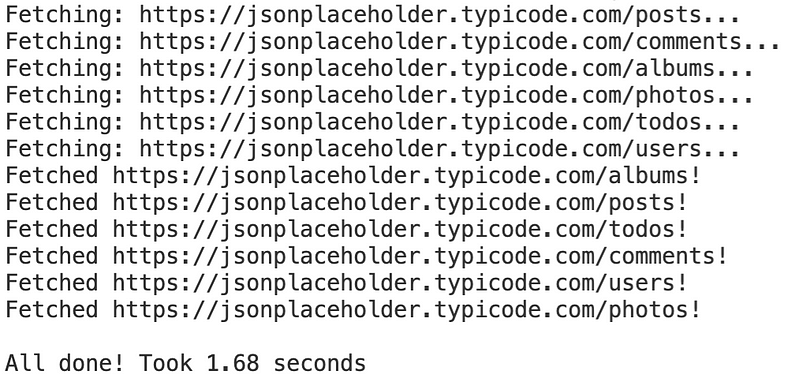
Image 2 — With multiprocessing script output (image by author)
The execution time took only 1.68 seconds, which is a significant improvement from what you had earlier. It’s concrete proof that tasks ran in parallel because sequential execution couldn’t finish in less than 6 seconds (sleep calls).
Conclusion
And there you have it — the most basic guide on process-based parallelism with Python. There are other ways to speed up your scripts that are based on concurrency, and these will be covered in the following articles.
Please let me know if you’d like to see more advanced parallelism tutorials. These would cover a real-life use case in data science and machine learning.
Thanks for reading.
Learn More
- Python If-Else Statement in One Line - Ternary Operator Explained
- Python Structural Pattern Matching - Top 3 Use Cases to Get You Started
- Dask Delayed - How to Parallelize Your Python Code With Ease
Stay connected
- Sign up for my newsletter
- Subscribe on YouTube
- Connect on LinkedIn