
Pandas Add Row to DataFrame
You have 3 options if you want to add row to DataFrame, and these are the append() method, loc[] indexer, and the concat() method. All three are kind of similar, but there are some differences you have to be aware of.
That’s where this article comes in, as it will show you how to add one row to Pandas DataFrame. You’ll also learn how to add list to DataFrame, how to append dictionary to DataFrame in Pandas, how to add rows from list, and much, much more.
Regarding library imports, you only need Pandas, so stick this line at the top of your script or notebook:
import pandas as pd
This is the dataset we’ll use in the article. It contains four made-up employees described over three features:
employees = {
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
}
data = pd.DataFrame(employees)
data
And this is what it looks like:
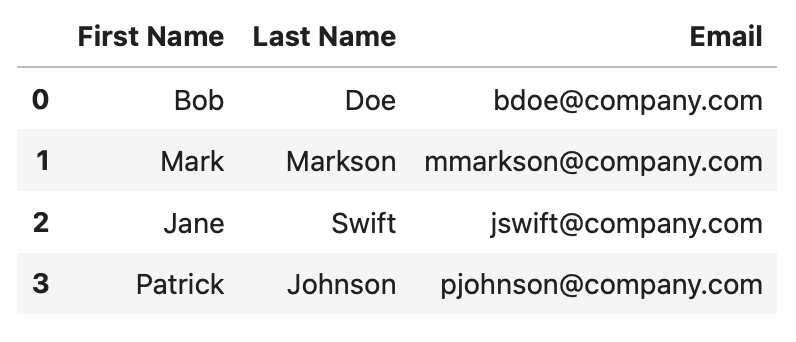
Image 1 - Starting dataset (Image by author)
Let’s start with the simplest way to add row to a Pandas DataFrame, which is by using the append() method.
Table of contents:
1. Add Row to Pandas DataFrame with the append() Method
You can use the append() method from Pandas to add one or more rows to an existing DataFrame. The method is called on a Pandas DataFrame object, which means you must have one DataFrame already declared.
Add Single Row to DataFrame with append()
To add a single row to our dataset, we’ll leverage Pandas to add row to DataFrame from dict. A new record is stored as a Python dictionary to a variable new_employee. You then have to call the append() method on the original dataset and provide the new row value:
# A single new employee
new_employee = {"First Name": "Joseph", "Last Name": "Dune", "Email": "[email protected]"}
# Add a single row using the append() method
data = data.append(new_employee, ignore_index=True)
data
The ignore_index=True argument means the DataFrame index will be reset after the new row is added. This is useful since we’re using a default index (range index), and we don’t want the sequence to break.
Anyhow, here’s what the DataFrame looks like:
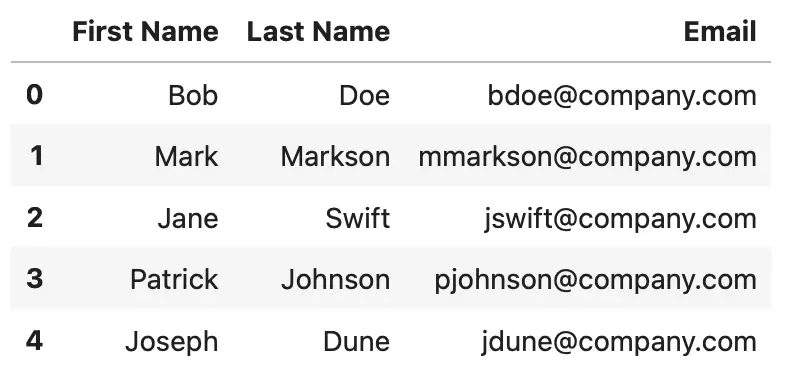
Image 2 - DataFrame after adding a single row with append() (Image by author)
We have a new row in the Pandas Dataframe, which means the append() method did its job. Let’s see how it can handle inserting multiple rows.
Add Multiple Rows to DataFrame with append()
If you want to use Pandas to add row to DataFrame from list, the append() method from Pandas is what you’re looking for.
The idea is to declare a list of dictionaries that follow the same pattern you saw in the previous section. Each list item represents one row that will be added to the Pandas DataFrame.
Here’s the entire code snippet for adding multiple rows to a Pandas DataFrame:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
# A list of 3 new employees
new_employees = [
{"First Name": "Joseph", "Last Name": "Dune", "Email": "[email protected]"},
{"First Name": "Jackie", "Last Name": "Slash", "Email": "[email protected]"},
{"First Name": "Ginni", "Last Name": "Mars", "Email": "[email protected]"}
]
# Add all three using the append() method
data = data.append(new_employees, ignore_index=True)
data
Our dataset now has six rows in total:
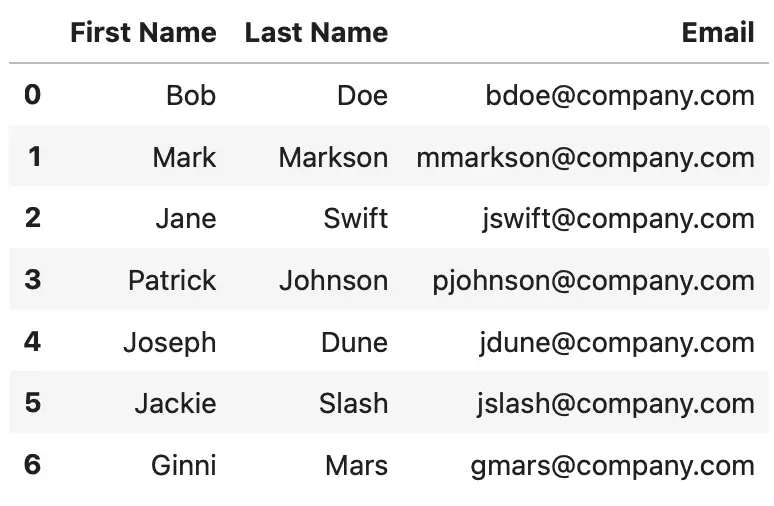
Image 3 - DataFrame after adding multiple rows with append() (Image by author)
That’s all for the append() method, and next, we’ll learn ins and outs of the loc[] indexer.
2. Pandas DataFrame Add Row with loc[]
The loc[] indexer in Pandas allows you to access a row, group of rows or columns, or a boolean array. This means you can use it to access particular rows and columns and their combinations, and in our case - to add one or more rows to the Dataframe.
Pandas DataFrame Insert Single Row with loc[]
You can use the loc[] indexer in Pandas to append a dictionary to DataFrame. It involves a bit more creative thinking than append() or concat(), since loc[] technically isn’t a method for that particular task.
To add a row to DataFrame using loc[], you need to index the row at the end of the DataFrame (using len(df)), and assign a new row to it.
Here’s the code snippet:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
# A single new employee
new_employee = {"First Name": "Jackie", "Last Name": "Slash", "Email": "[email protected]"}
# Add a single new employee using loc[]
data.loc[len(data)] = new_employee
data
The resulting DataFrame contains the new employee record now:
![Image 4 - DataFrame after adding a single row with loc[] (Image by author)](images/4.png)
Image 4 - DataFrame after adding a single row with loc[] (Image by author)
Adding one row is relatively easy, but what if you want to add more? Continue reading to find out.
Pandas DataFrame Insert Multiple Rows with loc[]
The loc[] indexer doesn’t allow you to add multiple rows at once, so you’ll have to add row to DataFrame in loop. That’s the only distinction when compared to adding a single row.
The following code snippet is simple to understand - we have a list of new employees that we iterate over, and then use the loc[] indexer to add each employee individually to the DataFrame:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
# A list of 3 new employees
new_employees = [
{"First Name": "Joseph", "Last Name": "Dune", "Email": "[email protected]"},
{"First Name": "Jackie", "Last Name": "Slash", "Email": "[email protected]"},
{"First Name": "Ginni", "Last Name": "Mars", "Email": "[email protected]"}
]
# All all three new employees using loc[]
for emp in new_employees:
data.loc[len(data)] = emp
data
The resulting Pandas DataFrame is identical to the one we had earlier:
Image 5 - DataFrame after adding multiple rows with loc[] (Image by author)
Truth be told - using loc[] to add row to Pandas DataFrame is just too much work. Let’s take a look at a more convenient approach next.
3. Add Row to DataFrame in Pandas with pd.concat()
The concat() method in Pandas is used to concatenate two Pandas DataFrame objects. Unlike append(), it’s not a DataFrame method, and it belongs to the Pandas library instead.
This method requires both elements to be of type pd.DataFrame, which means you’ll have to convert new records before concatenation. Not a dealbreaker, but just something to keep in mind.
DataFrame Insert Single with pd.concat()
Let’s begin by inserting a single row to a Pandas DataFrame with pd.concat(). The new_employee variable new contains a DataFrame object, which was created by wrapping a single employee dictionary into a Python list.
Then, you can use the pd.concat() method and pass in a list of DataFrame objects you want to be concatenated. The default orientation is row-wise, meaning DataFrames will be stacked on top of each other (horizontally). The ignore_index=True argument means the default range index will be reset after concatenation:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
# A single new employee, converted to Pandas DataFrame from a list
new_employee = pd.DataFrame([{"First Name": "Ginni", "Last Name": "Mars", "Email": "[email protected]"}])
# Adding a single new employee row using pd.concat()
data = pd.concat([data, new_employee], ignore_index=True)
data
This is what the resulting DataFrame looks like:
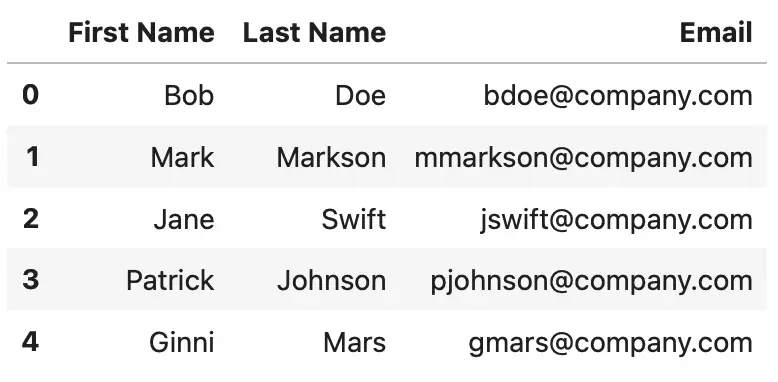
Image 6 - DataFrame after adding a single row with concat() (Image by author)
Up next, let’s see what are the challenges of adding multiple rows to a Pandas DataFrame.
DataFrame Insert Multiple Rows with pd.concat()
Adding multiple rows is almost identical to adding a single row. Remember, you already have a new Pandas DataFrame that’s made from list of dictionaries, so no one is stopping you from adding multiple records to that list.
Here’s an example in code:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
new_employees = pd.DataFrame([
{"First Name": "Joseph", "Last Name": "Dune", "Email": "[email protected]"},
{"First Name": "Jackie", "Last Name": "Slash", "Email": "[email protected]"},
{"First Name": "Ginni", "Last Name": "Mars", "Email": "[email protected]"}
])
# Add all three employees with pd.concat()
data = pd.concat([data, new_employees], ignore_index=True)
data
You’re already familiar with the resulting DataFrame, but here it is:
Image 7 - DataFrame after adding multiple rows with concat() (Image by author)
And that’s how easy it is to use the pd.concat() method. Let’s make a short recap next.
Summing up Pandas Add Row to DataFrame
There’s no shortage of ways to add one or more rows to a Pandas DataFrame. This article showed you three possible approaches, listed in no particular order.
So, which one is the best? There’s no correct answer to this question, but here’s our recommendation:
- Use
append()if you simply want to add one or more rows to a Pandas DataFrame - Use
concat()if you want to concatenate two, three, or even more Pandas DataFrame objects
The concat() method is more convenient when you’re dealing with multiple DataFrames, and append() shines for simpler use cases.
That’s our take, but what do you think? Feel free to share your opinions in the comment section below.