
Pandas Add Column to DataFrame
You have 7 options if you want to add a column to DataFrame, and these are by using Python lists, dictionaries, Pandas insert(), assign(), loc[], and apply() methods. Well, there are actually two ways to add columns to DataFrame in Pandas by using apply(), and you’ll learn both today.
Adding columns to a Pandas DataFrame is a must-know operation for any data analyst since it’s used all the time when preprocessing data for machine learning, driving insights from multiple features, combining multiple attributes, and so on. Overall, learn it sooner rather than later.
Want to add rows to a Pandas DataFrames? Here are 3 ways to do so.
Regarding library imports, you’ll only need Pandas, so stick this line at the top of your Python script or notebook:
import pandas as pd
And for the data, we’ll use a made-up Pandas DataFrame of four employees described by three features - first name, last name, and email:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
data
This is what the DataFrame looks like:
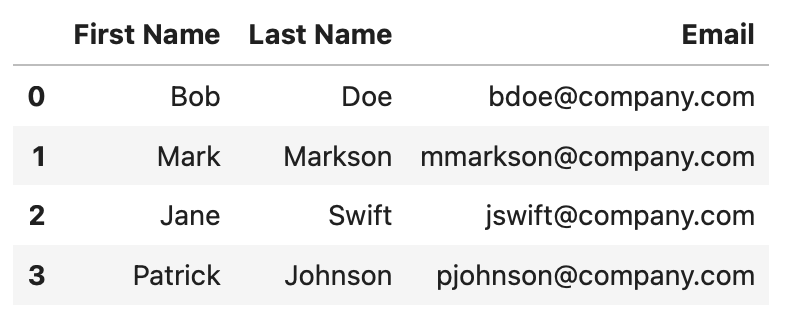
Image 1 - Starting dataset (Image by author)
Let’s get started with the first way to add a column to Pandas DataFrame, which is with plain Python lists.
Table of contents:
1. Pandas DataFrame Add Column from Python List
The first, and probably the easiest way to add a column to Pandas DataFrame is by using Python lists. You can either set a new column to have a constant value, or you can specify the value for each row.
We’ll explore both in this section.
Add Column to Pandas DataFrame With Default Value
A default value, or a constant value in a Pandas column means there’s only one distinct value in the entire feature. This is a useful approach if you know you’ll need the column, but don’t know the actual values at the time.
To demonstrate, we’ll assign a default value of 5th Street to a new column Office Address. Implementation in Pandas is as straightforward as it can be:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
data["Office Address"] = "5th Street"
data
Here’s what the resulting DataFrame looks like:
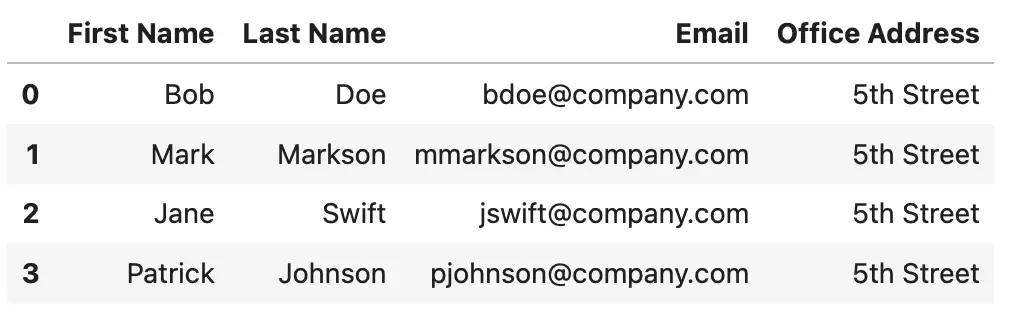
Image 2 - Pandas add column as a constant (Image by author)
Our new feature is here, but it’s not the most interesting one, and it doesn’t convey any information. Let’s see how to address this by assigning an entire list to a Pandas column.
Add Column to DataFrame from Python List
We’ll now declare a list of employee ages, and assign it to a new feature - age. The DataFrame is first restored to its original form to avoid any confusion.
Yes, you can create entire DataFrames from Python Lists - Here are 5 examples.
Here’s the code:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
ages = [33, 27, 31, 44]
data["Age"] = ages
data
And here’s the resulting Pandas DataFrame:
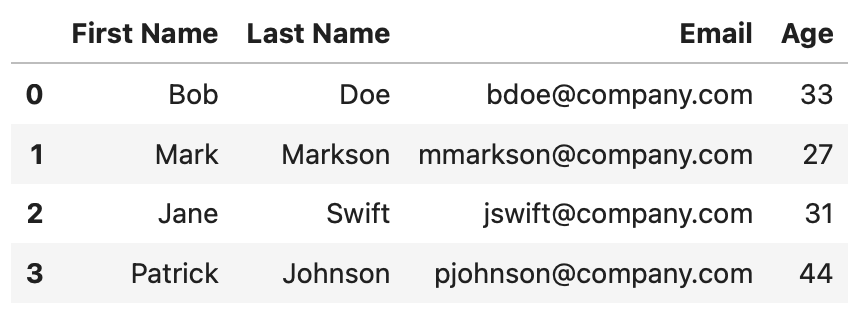
Image 3 - Add column to Pandas from Python list (Image by author)
The new column brings new information to the dataset, as it doesn’t store just a constant or default value.
That’s how you can add a new column to Pandas DataFrame with Python lists. Up next, let’s go over dictionaries.
2. Add Column to Pandas DataFrame from Python Dictionary
A dictionary is used to represent data in key-value pairs. For example, a dictionary key might be the user’s email, and the corresponding value could represent more details about the user, such as first name, last name, address, phone number, and so on.
Python dictionary to Pandas DataFrame? Here are 5 ways to make the conversion.
As it turns out, you can also convert a dictionary to a new column in a Pandas DataFrame. The notation is a bit confusing and may be too detailed for some users, so keep that in mind.
Dictionary keys have to be the values of a new column, and dictionary values must be possible values of a column that’s already present in the dataset. It’s a bit confusing, sure, but the example below will explain.
In the code snippet below, we’re assigning ages as dictionary keys, and emails as dictionary values. Emails already exist in the dataset, so that’s the column that will automatically get mapped:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
ages = {
33: "[email protected]",
27: "[email protected]",
31: "[email protected]",
44: "[email protected]"
}
data["Age"] = ages
data
Here’s the resulting DataFrame:
Image 4 - Add column to Pandas from Python dictionary (Image by author)
It’s identical to the one we had with lists, but with much less convenient code syntax. Use this approach to add new columns to a Pandas DataFrame if you must, but we don’t recommend it.
3. How to Add Column to a DataFrame in Python with the insert() Method
The insert() method from Pandas is likely the most versatile one you’ll see in this article, especially when it comes to inserting new columns into an existing DataFrame. It expects a couple of arguments:
loc- integer, represents the index at which the column will be insertedcolumn- string, name of the new columnvalue- scalar or list, simply a value for the new column
Let’s see how you can use the insert() method to add a new column of employee ages in front of all other attributes (loc=0):
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
ages = [33, 27, 31, 44]
data.insert(loc=0, column="Age", value=ages)
data
Here’s what the resulting DataFrame looks like:
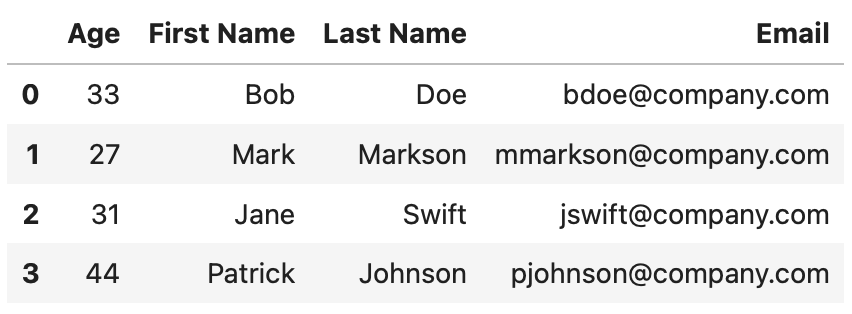
Image 5 - Add column to Pandas with the insert() method (Image by author)
In short, the insert() method allows us to change the position of the new column. But what if you want to insert a new column at the end of a Pandas DataFrame? You can use shape to determine the number of columns the DataFrame already has:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
ages = [33, 27, 31, 44]
data.insert(loc=data.shape[1], column="Age", value=ages)
data
The resulting DataFrame is the one you’re already used to seeing:
Image 6 - Add a column to DataFrame at a specific location with the insert() method (Image by author)
To summarize, insert() is simple to use and versatile, and we strongly recommend you use it at all times.
4. Add Column to DataFrame with the assign() Method
The assign() method is useful when you want to add a new column to Pandas DataFrame, but uses a slightly weird syntax. It can accept as many arguments as the number of columns you want to add at once, but you can’t specify column names as strings.
Take a look at the following example:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
ages = [33, 27, 31, 44]
data = data.assign(Age=ages)
data
The resulting DataFrame is identical to the ones we had before:
Image 7 - Add column to Pandas with the assign() method (Image by author)
The syntax behind this method is weird because you’re forced to use one-word column names or separate words with an underscore. It’s a minor design flaw, but luckily, there are other ways to add columns to a DataFrame.
5. Pandas Add Column with the loc[] Indexer
The loc[] indexer in Pandas is used to access a row, group of rows or columns, or a boolean array. This means you can use it to access particular rows and columns and their combinations, and in our case - to add one or more columns to a Dataframe.
Now, loc[] uses curly brackets which expect the row number and column name, separated by a comma. To add a new column with loc[], you can write : to affect all rows, followed by the name of your column.
Here’s an example:
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
ages = [33, 27, 31, 44]
data.loc[:, "Age"] = ages
data
Once again, you’re quite familiar with this dataset by now:
Image 8 - Add column to Pandas with the loc[] indexer (Image by author)
Overall, loc[] provides a neat way to add a new column to Pandas DataFrame. Is it more intuitive than insert() or even simple Python lists? Hardly, but you be the judge.
6. Pandas Add Column Value Based on Condition with apply()
If you’re wondering how to add a column to Pandas DataFrame based on another column, or how to add a column to a Dataframe based on a function in Pandas, look no further than the apply() method. It deserves a series of articles in itself, but we’ll keep things brief here and focus only on inserting new columns.
For example, you can use apply() to create a new column which is based on a Python function applied to an existing column.
The code snippet below declares a Python function is_short_first_name() which returns 1 if the string passed in has 5 or fewer characters, and 0 otherwise. We can then apply this function to an existing column - First Name - to create a new one:
def is_short_first_name(first_name: str) -> int:
if len(first_name) <= 5:
return 1
return 0
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
data["Has Short First Name?"] = data["First Name"].apply(is_short_first_name)
data
Here’s the resulting DataFrame:

Image 9 - Add column to Pandas based on a custom function (Image by author)
The apply() method is so powerful that you can even use it on multiple columns at once. Let’s see how next.
7. Pandas Create New Column from Existing Columns with apply()
The apply() method is often used with lambda functions, which are nothing more than anonymous functions. As it turns out, we can combine both custom Python functions and lambda functions to create a new column in a Pandas DataFrame that’s based on multiple existing columns.
To demonstrate, we’ll create a new Python function called get_full_email(). It takes the employee’s first and last name, which are then lowercased, joined with a dot in between, and concatenated with @company.com.
Now, we need access to both the First Name and Last Name attributes, so how can we do that? Well, we can call apply() on the entire DataFrame, and then pass in the columns of interest to get_full_email() while inside a lambda function.
It’s understandable if you’re confused at this point, so let’s go over an example in code:
def get_full_email(first_name: str, last_name: str) -> str:
return f"{first_name.lower()}.{last_name.lower()}@company.com"
data = pd.DataFrame({
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
})
data["Full Email"] = data.apply(lambda x: get_full_email(x["First Name"], x["Last Name"]), axis=1)
data
This is what the resulting DataFrame looks like:

Image 10 - Add column to Pandas based on custom function (2) (Image by author)
We now have a second version of the email, which is a dynamic combination of the corresponding First Name and Last Name attributes. Nice!
Summing up Pandas Add Column to DataFrame
To recap everything, there are more ways to add a column to DataFrame than you’ll ever need. We recommend you stick with Python lists or the insert() method, as these options are easy to use while providing enough versatility.
On the other side, the apply() function is all you need for 100% customization and advanced use cases. We’ll cover that function in much more depth soon, so stay tuned to Practical Pandas to learn more.
What’s your preferred way to add new columns to a Pandas DataFrame? Please let us know in the comment section below.