
Using machine learning algorithms to handle missing data
Missing value imputation isn’t that difficult of a task to do. Methods range from simple mean imputation and complete removing of the observation to more advanced techniques like MICE. Nowadays, the more challenging task is to choose which method to use. Today we’ll explore one simple but highly effective way to impute missing data — the KNN algorithm.
KNN stands for K-Nearest Neighbors, a simple algorithm that makes predictions based on a defined number of nearest neighbors. It calculates distances from an instance you want to classify to every other instance in the training set.
We won’t use the algorithm for classification purposes but to fill missing values, as the title suggests. The article will use the housing prices dataset, a simple and well-known one with just over 500 entries. You can download it here.
The article is structured as follows:
- Dataset loading and exploration
- KNN imputation
- Imputer optimization
- Conclusion
Dataset loading and exploration
As mentioned previously, you can download the housing dataset from this link. Also, make sure you have both Numpy and Pandas imported. This is how the first couple of rows look:
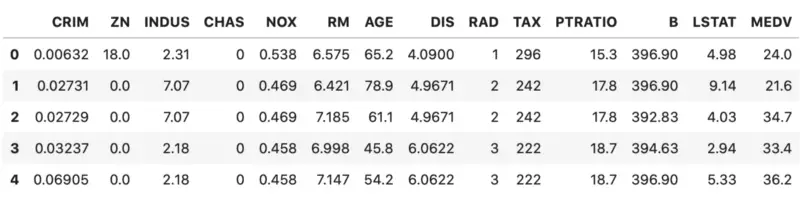
Image by author
By default, the dataset is very low on missing values — only five of them in a single attribute:

Image by author
Let’s change that. It’s not something you would typically do, but we need a bit more of missing values. To start, let’s create two arrays of random numbers, ranging from 1 to the length of the dataset. The first array has 35 elements, and the second has 20 (arbitrary choice):
i1 = np.random.choice(a=df.index, size=35)
i2 = np.random.choice(a=df.index, size=20)
Here’s how the first array looks like:

Image by author
Your array will be different because the randomization process is, well, random. Next, we will replace existing values at particular indices with NANs. Here’s how:
df.loc[i1, 'INDUS'] = np.nan
df.loc[i2, 'TAX'] = np.nan
Let’s now check again for missing values — this time, the count is different:

Image by author
That’s all we need to begin with imputation. Let’s do that in the next section.
KNN imputation
The entire imputation boils down to 4 lines of code — one of which is library import. We need KNNImputer from sklearn.impute and then make an instance of it in a well-known Scikit-Learn fashion. The class expects one mandatory parameter – n_neighbors. It tells the imputer what’s the size of the parameter K.
To start, let’s choose an arbitrary number of 3. We’ll optimize this parameter later, but 3 is good enough to start. Next, we can call the fit_transform method on our imputer to impute missing data.
Finally, we’ll convert the resulting array into a pandas.DataFrame object for easier interpretation. Here’s the code:
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=3)
imputed = imputer.fit_transform(df)
df_imputed = pd.DataFrame(imputed, columns=df.columns)
Wasn’t that easy? Let’s check for missing values now:

Image by author
As expected, there aren’t any. Still, one question remains —how do we pick the right value for K?
Imputer optimization
This housing dataset is aimed towards predictive modeling with regression algorithms, as the target variable is continuous (MEDV). It means we can train many predictive models where missing values are imputed with different values for K and see which one performs the best.
But first, the imports. We need a couple of things from Scikit-Learn — to split the dataset into training and testing subsets, train the model, and validate it. We’ve chosen the Random Forests algorithm for training, but the decision is once again arbitrary. RMSE was used for the validation:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
rmse = lambda y, yhat: np.sqrt(mean_squared_error(y, yhat))
Here are the steps necessary to perform the optimization:
- Iterate over the possible range for K — all odd numbers between 1 and 20 will do
- Perform the imputation with the current K value
- Split the dataset into training and testing subsets
- Fit the Random Forests model
- Predict on the test set
- Evaluate using RMSE
It sounds like a lot, but it boils down to around 15 lines of code. Here’s the snippet:
def optimize_k(data, target):
errors = []
for k in range(1, 20, 2):
imputer = KNNImputer(n_neighbors=k)
imputed = imputer.fit_transform(data)
df_imputed = pd.DataFrame(imputed, columns=df.columns)
X = df_imputed.drop(target, axis=1)
y = df_imputed[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestRegressor()
model.fit(X_train, y_train)
preds = model.predict(X_test)
error = rmse(y_test, preds)
errors.append({'K': k, 'RMSE': error})
return errors
We can now call the optimize_k function with our modified dataset (missing values in 3 columns) and pass in the target variable (MEDV):
k_errors = optimize_k(data=df, target='MEDV')
And that’s it! The k_errors array looks like this:
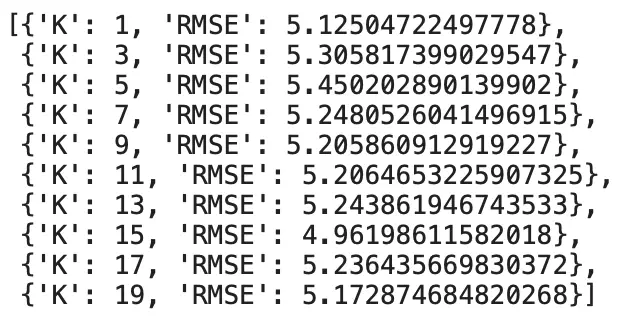
Image by author
Or, represented visually:
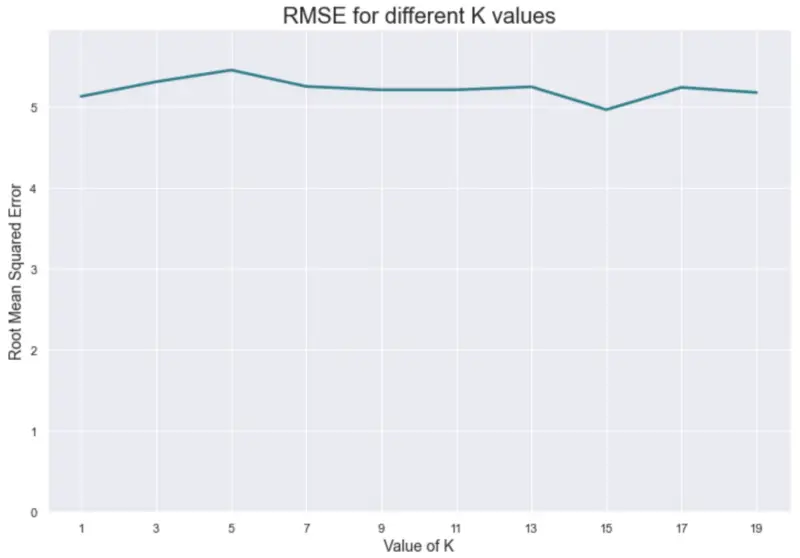
Image by author
It looks like K=15 is the optimal value in the given range, as it resulted in the smallest error. We won’t cover the interpretation of the error, as it’s beyond this article’s scope. Let’s wrap things up in the next section.
Parting words
Missing data imputation is easy, at least the coding part. It’s the reasoning that makes it hard — understanding which attributes should and which shouldn’t be imputed. For example, maybe some values are missing because a customer isn’t using that type of service, making no sense to perform an imputation.
Consulting with a domain expert and studying the domain is always a way to go. The actual coding is easy.