
Yes, SQL can do that. 5 lines of code required.
Machine learning isn’t reserved just for Python and R anymore. Much can be done directly in the database with the language everyone knows —SQL. Today we’ll explore how to use it to calculate feature importance, with around five lines of code.
We’ll use Oracle Cloud for this article. It’s free, so please register and create an instance of the OLTP database (Version 19c, has 0.2TB of storage). Once done, establish a connection through the SQL Developer Web— or any other tool.
As for the dataset, we’ll use a Telco industry churn dataset, available for download here. I’ve chosen this dataset because it has many features and doesn’t require any manual preparation.
The article is structured as follows:
- What is feature importance?
- Dataset loading
- Feature importance with SQL
- Conclusion
What is feature importance?
Feature importance is a technique that assigns a score to the input features (attributes) based on how useful they are for prediction (for predicting the target variable).
The concept is essential for predictive modeling because you want to keep only the important features and discard others. By doing so, you reduce both the dimensionality and the noise. It can also lead you to a better understanding of your data, for obvious reasons.
Further, calculating feature importance can provide insights into the workings of a predictive model. By knowing the importance scores, you can immediately tell what the model thinks is the most important, and why it makes predictions the way it does.
Additionally, it’s always good to have a quantitative confirmation, and not work on pure assumptions.
Dataset loading
If you are following along, you should have the dataset downloaded. You’ll have to load it into the database with a tool of your choice — I’m using the SQL Developer Web, but you can use pretty much anything.
The loading process is straightforward — click on the Upload button, choose the dataset, and click Next a couple of times:

Image 1 — Dataset loading with SQL Developer Web (image by author)
Mine is stored in the churn table. Let’s take a look at what’s inside by executing a SELECT * FROM churn statement:
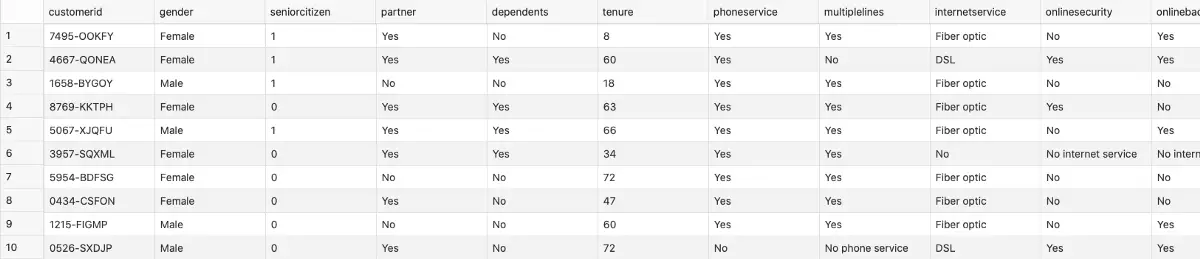
Image 2 — First 10 rows of the Churn dataset (image by author)
You can now proceed with the feature importance calculation.
Feature importance with SQL
As promised, this will take only a couple of lines of code. The feature importance is obtained through the EXPLAIN procedure of the DBMS_PREDICTIVE_ANALYTICS package. It expects three parameters:
data_table_name– where the source data is storedexplain_column_name– the name of the target variableresult_table_name– a new table where feature importances are stored
Here’s how to implement it in code:
BEGIN
DBMS_PREDICTIVE_ANALYTICS.EXPLAIN(
data_table_name => 'churn',
explain_column_name => 'churn',
result_table_name => 'churn_importances'
);
END;
/
And that’s it! You can now take a look at importances with a simple SELECT statement. The one below orders the features, so the most important ones are displayed first:
SELECT
attribute_name, explanatory_value, rank
FROM churn_importances
ORDER BY rank, attribute_name;
Here are the results:
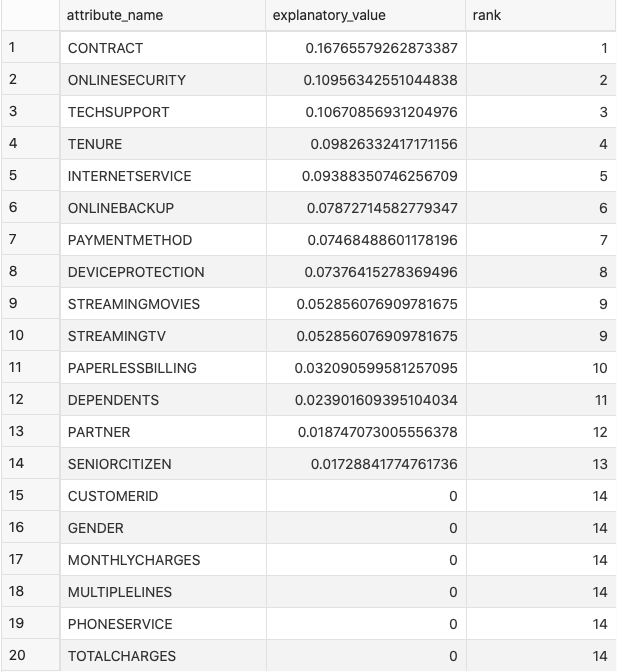
Image 3 — Feature importances (image by author)
From the previous image, you can immediately tell what is and what isn’t important. The next step would be to use this information for a predictive model. That’s a bit out of this article’s scope, but you’d want to proceed with the classification modeling.
As it turns out, this can also be performed only with SQL! Here’s how.
Parting words
I think you didn’t expect that feature importance calculation with SQL was this easy. But it is, just like the rest of in-database machine learning. SQL still isn’t a language for machine learning, but we can say that the future looks promising with these recent advancements.