
What is Standardization and why is it so darn important?
It’s possible that you will come across datasets with lots of numerical noise built-in, such as variance or differently-scaled data, so a good preprocessing is a must before even thinking about machine learning. A good preprocessing solution for this type of problem is often referred to as standardization.
Standardization is a preprocessing method used to transform continuous data to make it look normally distributed. In scikit-learn this is often a necessary step because many models assume that the data you are training on is normally distributed, and if it isn’t, your risk biasing your model.
You can standardize your data in different ways, and in this article, we’re going to talk about the popular data scaling method —data scaling. Or standard scaling to be more precise.
It’s also important to note that standardization is a preprocessing method applied to continuous, numerical data, and there are a few different scenarios in which you want to use it:
- When working with any kind of model that uses a linear distance metric or operates on a linear space — KNN, linear regression, K-means
- When a feature or features in your dataset have high variance — this could bias a model that assumes the data is normally distributed, if a feature in has a variance that’s an order of magnitude or greater than other features
Let’s now proceed with the data scaling.
Data scaling
Scaling is a method of standardization that’s most useful when working with a dataset that contains continuous features that are on different scales, and you’re using a model that operates in some sort of linear space (like linear regression or K-nearest neighbors)
Feature scaling transforms the features in your dataset so they have a mean of zero and a variance of one This will make it easier to linearly compare features. Also, this a requirement for many models in scikit-learn.
Let’s take a look at a dataset called wine:
import pandas as pd
import numpy as np
from sklearn import datasets
wine = datasets.load_wine()
wine = pd.DataFrame(
data=np.c_[wine['data'], wine['target']],
columns=wine['feature_names'] + ['target']
)
We want to use the ash, alcalinity_of_ash, and magnesium columns in the wine dataset to train a linear model, but it’s possible that these columns are all measured in different ways, which would bias a linear model. Using the describe() function returns descriptive statistics about the dataset:
wine[['magnesium', 'ash', 'alcalinity_of_ash']].describe()
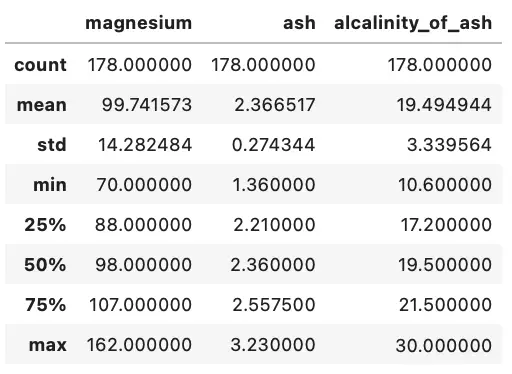
Image by author
We can see that the max of ash is 3.23, max of alcalinity_of_ash is 30, and a max of magnesium is 162. There are huge differences between the values, and a machine learning model could here easily interpret magnesium as the most important attribute, due to larger scale.
Let’s standardize them in a way that allows for the use in a linear model. Here are the steps:
- Import
StandardScalerand create an instance of it - Create a subset on which scaling is performed
- Apply the scaler fo the subset
Here’s the code:
from sklearn.preprocessing import StandardScaler
# create the scaler
ss = StandardScaler()
# take a subset of the dataframe you want to scale
wine_subset = wine[['magnesium', 'ash', 'alcalinity_of_ash']]
# apply the scaler to the dataframe subset
wine_subset_scaled = ss.fit_transform(wine_subset)
Awesome! Let’s see how the first couple of rows of scaled data look like:

Image by author
The values are now much closer together. To see how scaling actually impacts the model’s predictive power, let’s make a quick KNN model.
First, with the non-scaled data:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
X = wine.drop('target', axis=1)
y = wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
>>> 0.666666666666
Not so good of an accuracy. Let’s scale the entire dataset and repeat the process:
ss = StandardScaler()
X_scaled = ss.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y)
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
>>> 0.97777777777777777
As you can see, the accuracy of our model increased significantly. I’ll leave further tweaking of this KNN classifier up to you, and who knows, maybe you can get all the classifications correctly.
Let’s wrap things up in the next section.
Before you go
That’s pretty much it for data standardization and why it is important. We’ll compare StandardScaler with other scalers some other time. The take-home point of this article is that you should use StandardScalerwhenever you need normally distributed (relatively) features.
To be more precise, use StandardScaler whenever you’re using a model that assumes that the data is normally distributed - such as KNN or linear regression.
Thanks for reading.