
Sequential execution doesn’t always make sense. For example, there’s no point in leaving the program sitting idle if the outputs aren’t dependent on one another. That’s the basic idea behind concurrency— a topic you’ll learn a lot about today.
This article will teach you how you can speed up your Python code by running tasks concurrently. Keep in mind — concurrent execution doesn’t mean simultaneous. For more info on simultaneous (parallel) execution, check out this article.
This article is structured as follows:
- Introduction to threading
- Implementing threading — Sending 1000 requests
- The results
- Conclusion
You can download the source code for this article here.
Introduction to threading
So, what is threading precisely? Put simply, it’s a programming concept that allows you to run code concurrently. Concurrency means the application runs more than one task — the first task doesn’t have to finish before the second one is started.
Let’s say you’re making a bunch of requests towards some web API. It makes no sense to send one request, wait for the response, and repeat the same process over and over again.
Concurrency enables you to send the second request while the first one waits for the response. The following image should explain the idea behind sequential and concurrent execution better than words can:
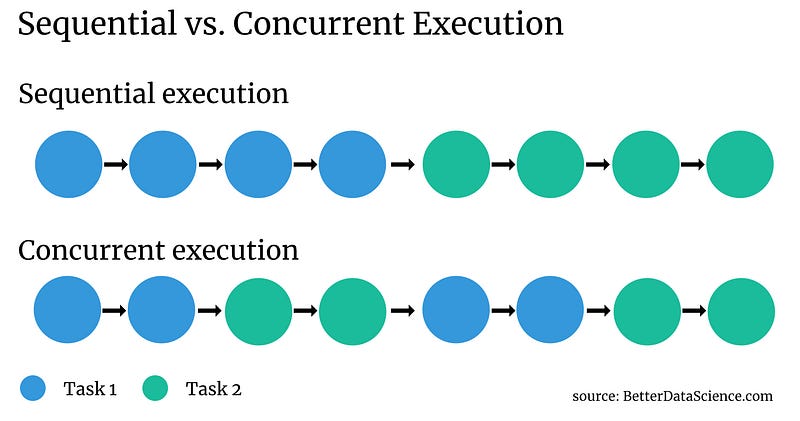
Image 1 — Sequential vs. concurrent execution (image by author)
Note that a single point represents a small portion of the task. Concurrency can help to speed up the runtime if the task sits idle for a while (think request-response type of communication).
You now know the basics of threading in theory. The following section will show you how to implement it in Python.
Implementing threading — Sending 1000 requests
Threading is utterly simple to implement with Python. But first, let’s describe the task.
We want to declare a function that makes a GET request to an endpoint and fetches some JSON data. The JSONPlaceholder website is perfect for the task, as it serves as a dummy API. We’ll repeat the process 1000 times and examine how long our program basically does nothing — waits for the response.
Let’s do the test without threading first. Here’s the script:
import time
import requests
URL = 'https://jsonplaceholder.typicode.com/posts'
def fetch_single(url: str) -> None:
print('Fetching...')
requests.get(url)
print('Fetched!')
time_start = time.time()
for _ in range(1000):
fetch_single(URL)
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
I reckon nothing should look unfamiliar in the above script. We’re repeating the request 1000 times and keeping track of start and end times. The print statements in the fetch_single() function are here for a single reason – to see how the program behaves when executed.
Here’s the output you’ll see after running this script:
Image 2 — Output of the sequential execution (image by author)
As you can see, one task has to finish for the other one to start. Not an optimal behavior for our type of problem.
Let’s implement threading next. The script will look more-or-less identical, with a couple of differences:
- We need an additional import —
concurrent.futures - We’re not printing the last statement but returning it instead
- The
ThreadPoolExecutor()is used for submitting and running tasks concurrently
Here’s the entire snippet:
import time
import requests
import concurrent.futures
URL = 'https://jsonplaceholder.typicode.com/posts'
def fetch_single(url: str):
print('Fetching...')
requests.get(url)
return 'Fetched!'
time_start = time.time()
with concurrent.futures.ThreadPoolExecutor() as tpe:
results = [tpe.submit(fetch_single, URL) for _ in range(1000)]
for f in concurrent.futures.as_completed(results):
print(f.result())
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
Once executed, you’ll see the output similar to this one:

Image 3 — Output of the concurrent execution (image by author)
That’s all great, but is there an actual speed improvement? Let’s examine that next.
The results
By now, you know the difference between sequential and concurrent execution and how to transform your code to execute function calls concurrently.
Let’s compare the runtime performance now. The following image summarizes runtime in seconds for the above task — making 1000 API calls:
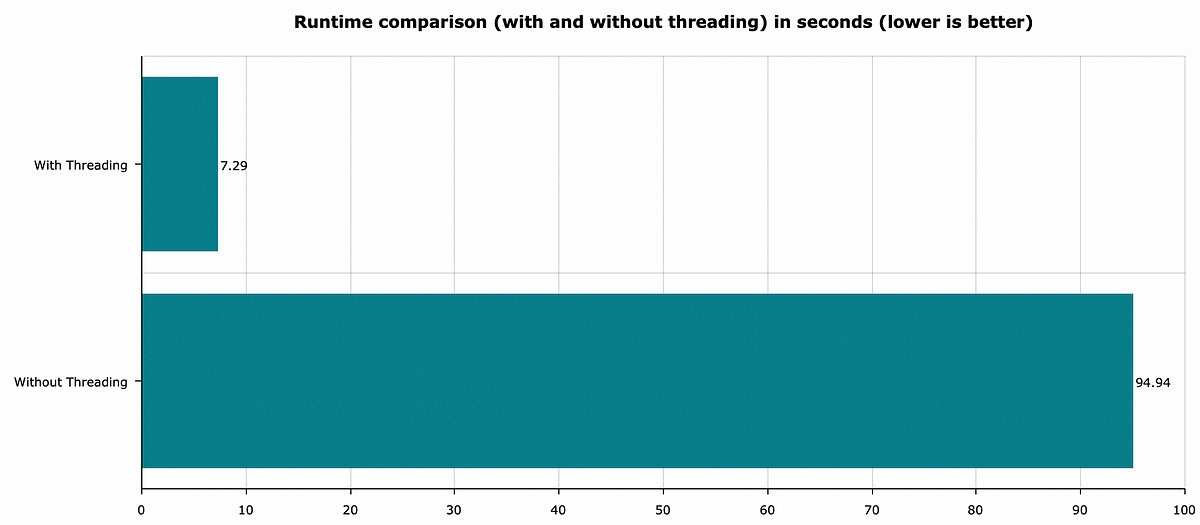
Image 4 — Runtime comparison with and without threading (image by author)
As you can see, there’s around a 13x reduction in execution time — decent, to say at least.
Conclusion
Today you’ve learned a lot — from the basic theory behind threading and concurrent execution to how you can “convert” your non-concurrent code into a concurrent-one.
Keep in mind that concurrency isn’t a be-all-end-all answer for speed increase with Python. Before implementing threading in your application, please consider how the app was designed. Is the output from one function directly fed as an input into another? If so, concurrency probably isn’t what you’re looking for.
On the other hand, if your app is sitting idle most of the time, “concurrent executing” might just be the term you’ve been waiting for.
Thanks for reading.
Stay connected
- Sign up for my newsletter
- Subscribe on YouTube
- Connect on LinkedIn